概述
- jar技术简介及使用
- Manifest文件
jar技术简介及使用
本文主要是参照Lesson: Packaging Programs in JAR Files来写,如果你的英文不错,可以直接看这个java官方教程。
在开始看下文你需要确认你安装的jdk环境带有jar命令,只需要在命令行中输入jar -h看看能不能找到命令即可。如果你安装的是oracle JDK,那么这个命令已经内置在java开发套件中。
下文所使用的源代码地址gihub
本文主要是参照Lesson: Packaging Programs in JAR Files来写,如果你的英文不错,可以直接看这个java官方教程。
在开始看下文你需要确认你安装的jdk环境带有jar命令,只需要在命令行中输入jar -h看看能不能找到命令即可。如果你安装的是oracle JDK,那么这个命令已经内置在java开发套件中。
下文所使用的源代码地址gihub
在研究spring源码之前我们首先需要搞明白一个概念,也就是Ioc,中文意思控制反转,从字面是看不出来这是什么,可以用来干嘛。但是spring的基础就是Ioc,如果理解不了Ioc,也就谈不上对spring的源码分析。所以首先我们要搞明白Ioc。
Java 5 并发库主要关注于异步任务的处理,它采用了这样一种模式,producer线程创建任务并且利用阻塞队列将其传递给任务的consumer。这种模型在Java7和8中进一步发展,并且开始支持另外一种风格的任务执行,那就是将任务的数据集分解为子集,每个子集都可以由独立且同质的子任务来负责处理。
这种风格的基础库也就是fork/join框架,它允许程序员规定数据集该如何进行分割,并且支持将子任务提交到默认的标准线程池中,也就是通用的ForkJoinPool。Java8中,fork/join并行功能借助并行流的机制变得更加具有可用性。但是,不是所有的问题都适合这种风格的并行处理:所处理的元素必须是独立的,数据集要足够大,并且在并行加速方面,每个元素的处理成本要足够高,这样才能补偿建立 fork/join 框架所消耗的成本。CompletableFuture 类则是 Java 8 在并行流方面的创新。
这里主要介绍下面我们需要使用的一些知识点,主要是为了是读者可以更好的理解。
所谓异步调用其实就是实现一个可无需等待被调用函数的返回值而让操作继续运行的方法。在Java语言中,简单的讲就是另启一个线程来完成调用中的部分计算,使调用继续运行或返回,而不需要等待计算结果。但调用者仍需要取线程的计算结果。
回调函数比较通用的解释是,它是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用为调用它所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外一方调用的,用于对该事件或条件进行响应。
回调函数的机制:
JDK5新增了Future接口,用于描述一个异步计算的结果。虽然Future以及相关使用方法提供了异步执行任务的能力,但是对于结果的获取却是很不方便,只能通过阻塞或者轮询的方式得到任务的结果。阻塞的方式显然和我们的异步编程的初衷相违背,轮询的方式又会耗费无谓的CPU资源,而且也不能及时地得到计算结果,为什么不能用观察者设计模式呢?即当计算结果完成及时通知监听者。
有一些开源框架实现了我们的设想,例如Netty的ChannelFuture类扩展了Future接口,通过提供addListener方法实现支持回调方式的异步编程。Netty中所有的I/O操作都是异步的,这意味着任何的I/O调用都将立即返回,而不保证这些被请求的I/O操作在调用结束的时候已经完成。取而代之地,你会得到一个返回的ChannelFuture实例,这个实例将给你一些关于I/O操作结果或者状态的信息。当一个I/O操作开始的时候,一个新的Future对象就会被创建。在开始的时候,新的Future是未完成的状态--它既非成功、失败,也非被取消,因为I/O操作还没有结束。如果I/O操作以成功、失败或者被取消中的任何一种状态结束了,那么这个Future将会被标记为已完成,并包含更多详细的信息(例如:失败的原因)。请注意,即使是失败和被取消的状态,也是属于已完成的状态。阻塞方式的示例代码如清单 1 所示。
1 | // Start the connection attempt. |
上面代码使用的是awaitUninterruptibly方法,源代码如清单2所示。
1 | publicChannelFutureawaitUninterruptibly() { |
1 | // 尝试建立一个连接 |
可以明显的看出,在异步模式下,上面这段代码没有阻塞,在执行 connect 操作后直接执行到**printTime(“异步时间”)**,随后connect完成,Future的监听函数输出 connect 操作完成。
非阻塞则是添加监听类 ChannelFutureListener,通过覆盖 ChannelFutureListener 的 operationComplete 执行业务逻辑。
1 | `public void addListener(final ChannelFutureListener listener) {`` ``if (listener == null) {`` ``throw new NullPointerException("listener");``}`` ``booleannotifyNow = false;`` ``synchronized (this) {`` ``if (done) {`` ``notifyNow = true;`` ``} else {`` ``if (firstListener == null) {`` ``//listener 链表头`` ``firstListener = listener;`` ``} else {`` ``if (otherListeners == null) {`` ``otherListeners = new ArrayList<``ChannelFutureListener``>(1);`` ``}`` ``//添加到 listener 链表中,以便操作完成后遍历操作`` ``otherListeners.add(listener);`` ``}`` ``......`` ``if (notifyNow) {`` ``//通知 listener 进行处理`` ``notifyListener(listener);`` ``}``}` |
这部分代码的逻辑很简单,就是注册回调函数,当操作完成后自动调用回调函数,就达到了异步的效果。
在Java 8中, 新增加了一个包含50个方法左右的类: CompletableFuture,提供了非常强大的Future的扩展功能,可以帮助我们简化异步编程的复杂性,提供了函数式编程的能力,可以通过回调的方式处理计算结果,并且提供了转换和组合CompletableFuture的方法。
如果想使用以前阻塞或者轮询方式来使用,依然可以通过CompletableFuture类来实现,因为CompleteableFuture实现了CompletionStage和Future 接口方,因此也支持这种方式。
CompletableFuture 类声明了 CompletionStage 接口,CompletionStage 接口实际上提供了同步或异步运行计算的舞台,所以我们可以通过实现多个 CompletionStage 命令,并且将这些命令串联在一起的方式实现多个命令之间的触发。
CompletableFuture类实现了CompletionStage和Future接口,所以你还是可以像以前一样通过阻塞或者轮询的方式获得结果,尽管这种方式不推荐使用。
1 | public T get() |
getNow有点特殊,如果结果已经计算完则返回结果或者抛出异常,否则返回给定的valueIfAbsent值。join返回计算的结果或者抛出一个unchecked异常(CompletionException),可以不进行捕捉,它和get对抛出的异常的处理有些细微的区别,你可以运行下面的代码进行比较:
1 | CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { |
尽管Future可以代表在另外的线程中执行的一段异步代码,但是你还是可以在本身线程中执行:
1 | public static CompletableFuture<Integer> compute() { |
上面的代码中future没有关联任何的Callback、线程池、异步任务等,如果客户端调用future.get就会一直傻等下去。你可以通过下面的代码完成一个计算,触发客户端的等待:
1 | f.complete(100); |
当然你也可以抛出一个异常,而不是一个成功的计算结果:
1 | f.completeExceptionally(new Exception()); |
完整的代码如下:
1 | public class BasicMain { |
可以看到我们并没有把f.complete(100);放在另外的线程中去执行,但是在大部分情况下我们可能会用一个线程池去执行这些异步任务。CompletableFuture.complete()、CompletableFuture.completeExceptionally只能被调用一次。但是我们有两个后门方法可以重设这个值:obtrudeValue、obtrudeException,但是使用的时候要小心,因为complete已经触发了客户端,有可能导致客户端会得到不期望的结果。
CompletableFuture.completedFuture是一个静态辅助方法,用来返回一个已经计算好的CompletableFuture。
1 | public static <U> CompletableFuture<U> completedFuture(U value) |
而以下四个静态方法用来为一段异步执行的代码创建CompletableFuture对象:
1 | public static CompletableFuture<Void> runAsync(Runnable runnable) |
以Async结尾并且没有指定Executor的方法会使用ForkJoinPool.commonPool()作为它的线程池执行异步代码。
runAsync方法也好理解,它以Runnable函数式接口类型为参数,所以CompletableFuture的计算结果为空。
supplyAsync方法以Supplier<U>函数式接口类型为参数,CompletableFuture的计算结果类型为U。
因为方法的参数类型都是函数式接口,所以可以使用lambda表达式实现异步任务,比如:
1 | CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> { |
当CompletableFuture的计算结果完成,或者抛出异常的时候,我们可以执行特定的Action。主要是下面的方法:
1 | public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action) |
可以看到Action的类型是BiConsumer<? super T,? super Throwable>,它可以处理正常的计算结果,或者异常情况。
方法不以Async结尾,意味着Action使用相同的线程执行,而Async可能会使用其它的线程去执行(如果使用相同的线程池,也可能会被同一个线程选中执行)。
注意这几个方法都会返回CompletableFuture,当Action执行完毕后它的结果返回原始的CompletableFuture的计算结果或者返回异常。
1 | public class Main { |
exceptionally方法返回一个新的CompletableFuture,当原始的CompletableFuture抛出异常的时候,就会触发这个CompletableFuture的计算,调用function计算值,否则如果原始的CompletableFuture正常计算完后,这个新的CompletableFuture也计算完成,它的值和原始的CompletableFuture的计算的值相同。也就是这个exceptionally方法用来处理异常的情况。
下面一组方法虽然也返回CompletableFuture对象,但是对象的值和原来的CompletableFuture计算的值不同。当原先的CompletableFuture的值计算完成或者抛出异常的时候,会触发这个CompletableFuture对象的计算,结果由BiFunction参数计算而得。因此这组方法兼有whenComplete和转换的两个功能。
1 | public <U> CompletableFuture<U> handle(BiFunction<? super T,Throwable,? extends U> fn) |
同样,不以Async结尾的方法由原来的线程计算,以Async结尾的方法由默认的线程池ForkJoinPool.commonPool()或者指定的线程池executor运行。
CompletableFuture可以作为monad(单子)和functor。由于回调风格的实现,我们不必因为等待一个计算完成而阻塞着调用线程,而是告诉CompletableFuture当计算完成的时候请执行某个function。而且我们还可以将这些操作串联起来,或者将CompletableFuture组合起来。
1 | public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn) |
这一组函数的功能是当原来的CompletableFuture计算完后,将结果传递给函数fn,将fn的结果作为新的CompletableFuture计算结果。因此它的功能相当于将CompletableFuture<T>转换成CompletableFuture<U>。
这三个函数的区别和上面介绍的一样,不以Async结尾的方法由原来的线程计算,以Async结尾的方法由默认的线程池ForkJoinPool.commonPool()或者指定的线程池executor运行。Java的CompletableFuture类总是遵循这样的原则,下面就不一一赘述了。
使用例子如下:
1 | CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { |
需要注意的是,这些转换并不是马上执行的,也不会阻塞,而是在前一个stage完成后继续执行。
它们与handle方法的区别在于handle方法会处理正常计算值和异常,因此它可以屏蔽异常,避免异常继续抛出。而thenApply方法只是用来处理正常值,因此一旦有异常就会抛出。
上面的前一个CompleteFuture执行完成执行后一个,下面的是同时执行或者其中一个执行完成就代表执行完成。
1 | public <U> CompletableFuture<U> thenCompose(Function<? super T,? extends |
这一组方法接受一个Function作为参数,这个Function的输入是当前的CompletableFuture的计算值,返回结果将是一个新的CompletableFuture,这个新的CompletableFuture会组合原来的CompletableFuture和函数返回的CompletableFuture。因此它的功能类似:
1 | A +--> B +---> C |
记住,thenCompose返回的对象并不一定是函数fn返回的对象,如果原来的CompletableFuture还没有计算出来,它就会生成一个新的组合后的CompletableFuture。
例子:
1 | CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { |
而下面的一组方法thenCombine用来复合另外一个CompletionStage的结果。它的功能类似:
1 | A + |
两个CompletionStage是并行执行的,它们之间并没有先后依赖顺序,other并不会等待先前的CompletableFuture执行完毕后再执行。
1 | public <U,V> CompletableFuture<V> thenCombine(CompletionStage<? extends U> other, |
其实从功能上来讲,它们的功能更类似thenAcceptBoth,只不过thenAcceptBoth是纯消费,它的函数参数没有返回值,而thenCombine的函数参数fn有返回值。
1 | CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { |
上面的方法是当计算完成的时候,会生成新的计算结果(thenApply, handle),或者返回同样的计算结果whenComplete,CompletableFuture还提供了一种处理结果的方法,只对结果执行Action,而不返回新的计算值,因此计算值为Void:
1 | public CompletableFuture<Void> thenAccept(Consumer<? super T> action) |
看它的参数类型也就明白了,它们是函数式接口Consumer,这个接口只有输入,没有返回值。
1 | CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { |
thenAcceptBoth以及相关方法提供了类似的功能,当两个CompletionStage都正常完成计算的时候,就会执行提供的action,它用来组合另外一个异步的结果。
runAfterBoth是当两个CompletionStage都正常完成计算的时候,执行一个Runnable,这个Runnable并不使用计算的结果。
1 | public <U> CompletableFuture<Void> thenAcceptBoth(CompletionStage<? extends U> other, |
例子如下:
1 | CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { |
更彻底地,下面一组方法当计算完成的时候会执行一个Runnable,与thenAccept不同,Runnable并不使用CompletableFuture计算的结果。
1 | public CompletableFuture<Void> thenRun(Runnable action) |
因此先前的CompletableFuture计算的结果被忽略了,这个方法返回CompletableFuture<Void>类型的对象。
1 | CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> { |
因此,你可以根据方法的参数的类型来加速你的记忆。
Runnable类型的参数会忽略计算的结果,Consumer是纯消费计算结果,BiConsumer会组合另外一个CompletionStage纯消费,Function会对计算结果做转换,BiFunction会组合另外一个CompletionStage的计算结果做转换。
thenAcceptBoth和runAfterBoth是当两个CompletableFuture都计算完成,而我们下面要了解的方法是当任意一个CompletableFuture计算完成的时候就会执行。
1 | public CompletableFuture<Void> acceptEither(CompletionStage<? extends T> other, Consumer<? super T> action) |
acceptEither方法是当任意一个CompletionStage完成的时候,action这个消费者就会被执行。这个方法返回CompletableFuture
applyToEither方法是当任意一个CompletionStage完成的时候,fn会被执行,它的返回值会当作新的CompletableFuture的计算结果。
下面这个例子有时会输出100,有时候会输出200,哪个Future先完成就会根据它的结果计算。
1 | Random rand = new Random(); |
allOf 和 anyOf前面我们已经介绍了几个静态方法:completedFuture、runAsync、supplyAsync,下面介绍的这两个方法用来组合多个CompletableFuture。
1 | public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs) |
allOf方法是当所有的CompletableFuture都执行完后执行计算。
anyOf方法是当任意一个CompletableFuture执行完后就会执行计算,计算的结果相同。
下面的代码运行结果有时是100,有时是”abc”。但是anyOf和applyToEither不同。anyOf接受任意多的CompletableFuture但是applyToEither只是判断两个CompletableFuture,anyOf返回值的计算结果是参数中其中一个CompletableFuture的计算结果,applyToEither返回值的计算结果却是要经过fn处理的。当然还有静态方法的区别,线程池的选择等。
1 | Random rand = new Random(); |
我想通过上面的介绍,应该把CompletableFuture的方法和功能介绍完了(cancel、isCompletedExceptionally()、isDone()以及继承于Object的方法无需介绍了, toCompletableFuture()返回CompletableFuture本身),希望你能全面了解CompletableFuture强大的功能,并将它应用到Java的异步编程中。如果你有使用它的开源项目,可以留言分享一下。
Java引用体系中我们最熟悉的就是强引用类型,如 A a= new A();这是我们经常说的强引用StrongReference,jvm gc时会检测对象是否存在强引用,如果存在由根对象对其有传递的强引用,则不会对其进行回收,即使内存不足抛出OutOfMemoryError。
除了强引用外,Java还引入了SoftReference(软引用),WeakReference(弱引用),PhantomReference(虚引用),FinalReference ,这些类放在java.lang.ref包下,类的继承体系如下图。
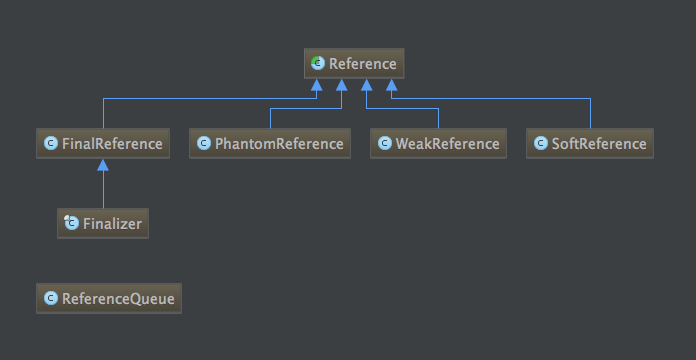
Java额外引入这个四种类型引用主要目的是在jvm在gc时,按照引用类型的不同,在回收时采用不同的逻辑。可以把这些引用看作是对对象的一层包裹,jvm根据外层不同的包裹,对其包裹的对象采用不同的回收策略,或特殊逻辑处理。 这几种类型的引用主要在jvm内存缓存、资源释放、对象可达性事件处理等场景会用到。
Java对象引用体系除了强引用之外,出于对性能、可扩展性等方面考虑还特地实现了4种其他引用:SoftReference、WeakReference、PhantomReference、FinalReference,本文主要想讲的是FinalReference,因为当使用内存分析工具,比如zprofiler、mat等,分析一些oom的heap时,经常能看到 java.lang.ref.Finalizer占用的内存大小远远排在前面,而这个类占用的内存大小又和我们这次的主角FinalReference有着密不可分的关系。
FinalReference及关联的内容可能给我们留下如下印象:
Finalizer的Java线程;java.lang.ref.Finalizer的存在;finalize方法。那FinalReference到底存在的意义是什么,以怎样的形式和我们的代码相关联呢?这是本文要理清的问题。
这里只对这三个类做个简单的总结,如果你希望详细了解这三个类,可以看一下三篇文章,我觉得写得很好。
首先一个简单的对比
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
StringBuffer与StringBuilder的实现几乎是一样的,只是StringBufferr为了保证线程安全,在方法前面加上Synchronize关键字来保证安全性,StringBuilder是在Jdk1.5之后才出现的,因此下面先用StringBuffer来和String进行对比
String类型和StringBuffer类型俩者都是线程安全,主要区别其实在于String是不可变的对象, 因此在每次对String类型进行改变的时候其实都等同于生成了一个新的String对象,然后将指针指向新的String对象,所以经常改变内容的字符串最好不要用String,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM的GC就会开始工作,那速度是一定会相当慢的。
而如果是使用StringBuffer类则结果就不一样了,每次结果都会对StringBuffer对象本身进行操作,而不是生成新的对象,再改变对象引用。所以在一般情况下我们推荐使用StringBuffer,特别是字符串对象经常改变的情况下。而在某些特别情况下,String对象的字符串拼接其实是被JVM解释成了StringBuffer对象的拼接,所以这些时候String对象的速度并不会比StringBuffer对象慢,而特别是以下的字符串对象生成中, String效率是远要比StringBuffer快:
1 | String S1 = “This is only a” + “ simple” + “ test”; |
测试结果:
1 | Benchmark Mode Cnt Score Error Units |
其中score对应是每次操作花费的纳秒数你会很惊讶的发现,生成S1对象的速度简直太快了,而这个时候StringBuffer居然速度上根本一点都不占优势。其实这是JVM做的一次优化,在JVM眼里,这个String S1 = “This is only a” + “ simple” + “test”;其实就是:String S1 = “This is only a simple test”; 所以拼接速度很快。但大家这里要注意的是,如果你的字符串是来自另外的String对象的话,速度就没那么快了,下面就是一个例子:
1 | String S2 = “This is only a”; |
这时候 JVM 会规规矩矩的按照原来的方式去做,在大部分情况下StringBuffer的性能要好于String。
StringBuffer
Java.lang.StringBuffer线程安全的可变字符序列。虽然在任意时间点上它都包含某种特定的字符序列,但通过某些方法调用可以改变该序列的长度和内容。可将字符串缓冲区安全地用于多个线程。可以在必要时对这些方法进行同步,因此任意特定实例上的所有操作就好像是以串行顺序发生的,该顺序与所涉及的每个线程进行的方法调用顺序一致。StringBuffer上的主要操作是append和insert方法,可重载这些方法,以接受任意类型的数据。每个方法都能有效地将给定的数据转换成字符串,然后将该字符串的字符追加或插入到字符串缓冲区中。append方法始终将这些字符添加到缓冲区的末端;而insert方法则在指定的点添加字符。
StringBuilder
java.lang.StringBuilder一个可变的字符序列,是5.0新增的。此类提供一个与StringBuffer兼容的 API,但不保证同步。该类被设计用作StringBuffer的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比StringBuffer要快。两者的方法基本相同。
测试性能源码(使用了JMH来进行基准测试)
1 |
|
测试结果
1 | Benchmark Mode Cnt Score Error Units |
从结果可以验证,在上面简单介绍中所说的,如果字符串拼接操作,最好选择StringBuilder,如果要保证线程安全选择StringBuffer,另外上面结果有一点需要注意的是,从测试结果看,StringBuffer和StringBuilder的性能差不多,这是因为我是在jdk8上运行并且只有一个线程,因此对Synchronize做了优化,使得StringBuffer性能得到提升。
我觉得这篇文章已经写得非常好因此可以看这篇文章
String:字符串常量池
但是我对这个持有疑问
String str2 = new String(“ABC”) + “ABC” ; 会创建多少个对象?
str2 :
字符串常量池:”ABC” : 1个
堆:new String(“ABC”) :1个
引用: str2 :1个
总共 : 3个
我认为结果是这样的:
字符串常量池 “ABC” 1个
堆:new String(“ABC”),new String(“ABCABC”),new StringBuilder()
new String(“ABCABC”) 是由于new String(“ABC”)+”ABC”在编译的时候会按照下面这种方式来生成
1 | StringBuilder stringBuilder = new StringBuilder(); |
另外由于这个是使用new String(“ABC”) + “ABC”,因此ABCABC不会进入常量池,除非调用String.intern()方法
不知道对不对,欢迎大家讨论
此篇博客主要为记录学习使用
在研究过程中主要参考如下俩篇文章
自旋锁与互斥量(注意这里不是互斥锁)类似,用于多线程同步的一种锁。但他不是休眠使线程阻塞,而是在获取锁之前一直处于忙等(自旋)阻塞状态。基本的实现是通过线程反复检查锁特定变量是否可用。由于线程在这一过程中保持执行,因此是一种忙等待。一旦获取了自旋锁,线程会一直保持该锁,直至显式释放自旋锁。
自旋锁通常被作为底层原语用于实现其他类型的锁。根据它们所基于与的系统体系结构,可以通过使用测试并设置指令(CAS)有效的实现。当然这里说的有效也还是会导致CPU资源的浪费:当线程自旋等待锁变为可用时,CPU不能做其它的事情,这也是自旋锁只能够持有一段时间的原因。
有了这一层了解,自旋锁的优势和劣势,以及其适用场景也就一目了然了。
首先,如果你看到这篇文章相信对这俩个类有一定的了解,所以我就不再这里介绍具体的用法。简单的介绍一下这个类,Random,ThreadLocalRandom是Java中的随机数生成器,Random是我们比较常用的随机数生成器,他是线程安全的。ThreadLocalRandom是jdk7才出现的,是Random的增强版。在并发访问的环境下,使用ThreadLocalRandom来代替Random可以减少多线程竞争,同时也能保证线程安全和提高性能。
由于本人能力有限,如果你的英文比较好,可以看看StackOverFlow上的这个讨论https://stackoverflow.com/questions/23396033/random-over-threadlocalrandom
我使用的JMH来进行的压测,这篇文章可以帮助你入门 JMH。具体代码如下
1 | /************************************** |
测试结果
1 | ··· 前面一部分省略,主要内容如下 |
从上面结果可以看出,结果验证确实ThreadLocalRandom在多线程环境情况下更快,ThreadLocalRandom比Random快了将近13倍之多。
至于为什么ThreadLocalRandom更快呢,这个要从源码来分析。
Random的实现也比较简单,初始化的时候用当前的事件来初始化一个随机数种子,然后每次取值的时候用这个种子与有些MagicNumber运算,并更新种子。最核心的就是这个next的函数,不管你是调用了nextDouble还是nextInt还是nextBoolean,Random底层都是调这个next(int bits)。
1 | protected int next(int bits) { |
为了保证多线程下每次生成随机数都是用的不同,next()得保证seed的更新是原子操作,所以用了AtomicLong的compareAndSet(),该方法底层调用了sum.misc.Unsafe的compareAndSwapLong(),也就是大家常听到的CAS, 这是一个native方法,它能保证原子更新一个数。
既然Random是线程安全的,又能满足我们大多说的要求,为什么concurrent包里还要实现一个ThreadLocalRandom。在oracle的jdk文档里发现这样一句话
use of ThreadLocalRandom rather than shared Random objects in concurrent programs will typically encounter much less overhead and contention. Use of ThreadLocalRandom is particularly appropriate when multiple tasks (for example, each a ForkJoinTask) use random numbers in parallel in thread pools.
大意就是用ThreadLocalRandom更适合用在多线程下,能大幅减少多线程并行下的性能开销和资源争抢。
既然ThreadLocalRandom在多线程下表现这么牛逼,它究竟是如何做到的?我们来看下源码,它的核心代码是这个(在看源码时需要注意一点,虽然ThreadLocalRandom也实现了next函数,但是在这个函数上面有一句,定义了这个方法,但绝不使用,你也可以从next*方法里面看出,使用的都是mix32(nextSeed)或者mix64(nextSeed)来获取随机数)
1 | final long nextSeed() { |
上面虽然使用了UNSAFE对象,但是没有调用CAS方法,只是简单的替换Thread对象中的threadLocalRandomSeed属性,所以不要一看到UNSAFE这个类,就当成要调用CAS方法,我刚开始阅读的时候就有这个疑惑,自己太菜了。
在创建ThreadLocalRandom对象时,ThreadLocalRandom是对每个线程都设置了单独的随机数种子,这样就不会发生多线程同时更新一个数时产生的资源争抢了,用空间换时间。
在生成验证码的情况下,不要使用Random,因为它是线性可预测的。所以在安全性要求比较高的场合,应当使用SecureRandom。从理论上来说计算机产生的随机数都是伪随机数,要想产生高强度的随机数,有两个重要的因素:种子和算法。当然算法是可以有很多的,但是如何选择种子是非常关键的因素。如Random,它的种子是System.currentTimeMillis(),所以它的随机数都是可预测的。那么如何得到一个近似随机的种子?这里有一个很别致的思路:收集计算机的各种信息,如键盘输入时间,CPU时钟,内存使用状态,硬盘空闲空间,IO延时,进程数量,线程数量等信息,来得到一个近似随机的种子。这样的话,除了理论上有破解的可能,实际上基本没有被破解的可能。而事实上,现在的高强度的随机数生成器都是这样实现的。