cache简介
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
CPU cache 有什么意义?cache的容量远远小于主存,因此出现 cache miss 在所难免,既然 cache不能包含CPU所需要的所有数据,那么cache的存在真的有意义吗?当然是有意义的——局部性原理。
- 时间局部性:如果某个数据被访问,那么在不久的将来它很可能被再次访问;
- 空间局部性:如果某个数据被访问,那么与它相邻的数据很快也可能被访问;
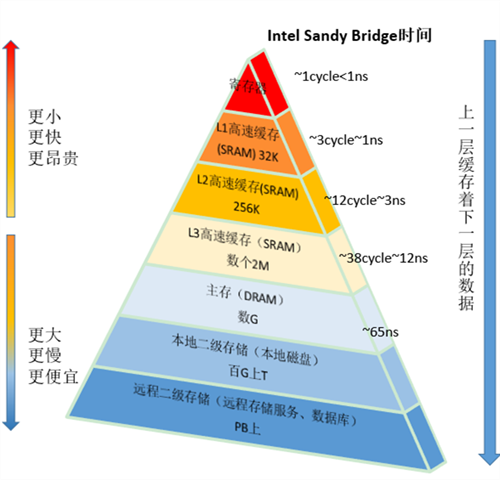
下图是Intel cpu的存储器架构图
按照数据读取顺序和与CPU结合的紧密程度,CPU缓存可以分为一级缓存,二级缓存,部分高端 CPU还具有三级缓存。不过目前几乎使用的笔记本都已经使用了三级缓存。每一级缓存中所储存的全部数据都是下一级缓存的一部分,越靠近CPU的缓存越快也越小。所以L1缓存很小但很快(译注:L1 表示一级缓存),并且紧靠着在使用它的CPU内核。L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用。L3 在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有CPU核共享。最后,你拥有一块主存,由全部插槽上的所有CPU核共享。拥有三级缓存的的 CPU,到三级缓存时能够达到 95% 的命中率,只有不到 5% 的数据需要从内存中查询。
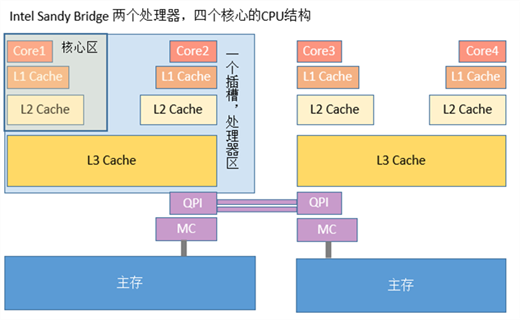
计算机早已进入多核时代,软件也越来越多的支持多核运行。一个处理器对应一个物理插槽,多处理器间通过QPI总线相连。一个处理器包含多个核,一个处理器间的多核共享L3 Cache。一个核包含寄存器、L1 Cache、L2 Cache,下图是Intel Sandy Bridge CPU架构,一个典型的NUMA多处理器结构:
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在 L1 缓存中。
Martin Thompson给出了一些缓存未命中的消耗数据,如下所示: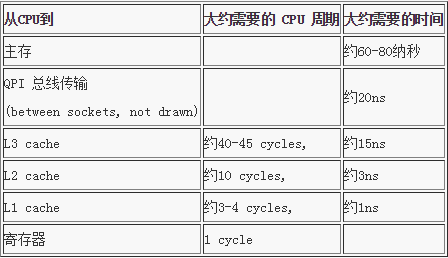
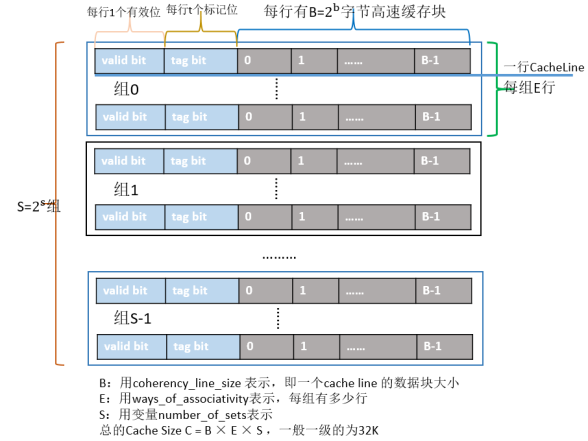
cache结构
Cache的结构下图所示:整个Cache被分为S个组,每个组是又由E行个最小的存储单元——Cache Line所组成,而一个Cache Line中有B(B=64)个字节用来存储数据,即每个Cache Line能存储64个字节的数据,每个Cache Line又额外包含一个有效位(valid bit)、t个标记位(tag bit),其中valid bit用来表示该缓存行是否有效;tag bit用来协助寻址,唯一标识存储在CacheLine中的块;而Cache Line里的64个字节其实是对应内存地址中的数据拷贝。根据Cache的结构题,我们可以推算出每一级Cache的大小为B×E×S。
cache 一致性
缓存一致性:在多核CPU中,内存中的数据会在多个核心中存在数据副本,某一个核心发生修改操作,就产生了数据不一致的问题。而一致性协议正是用于保证多个CPU cache之间缓存共享数据的一致。
至于 MESI,则是缓存一致性协议中的一个,到底怎么实现,还是得看具体的处理器指令集。
这里只是简单介绍,不会具体的深入如何实现的。
cache 写的方式
cache 的写操作方式主要有下面俩种。
- write through(写通):每次CPU修改了cache中的内容,立即更新到内存,也就意味着每次CPU写共享数据,都会导致总线事务,因此这种方式常常会引起总线事务的竞争,高一致性,但是效率非常低;
- write back(写回):每次 CPU 修改了cache中的数据,不会立即更新到内存,而是等到 cache line在某一个必须或合适的时机才会更新到内存中;
无论是写通还是写回,在多线程环境下都需要处理缓存cache一致性问题。为了保证缓存一致性,处理器又提供了写失效(write invalidate)和写更新(write update)两个操作来保证cache 一致性。
写失效:当一个CPU修改了数据,如果其他CPU有该数据,则通知其为无效;
写更新:当一个CPU修改了数据,如果其他CPU有该数据,则通知其跟新数据;
写更新会导致大量的更新操作,因此在 MESI 协议中,采取的是写失效(即 MESI 中的 I:ivalid,如果采用的是写更新,那么就不是 MESI 协议了,而是 MESU 协议)。
cache line状态介绍
上面已经介绍,cache是由一个个的cache line组成,而且cache line是cache与内存数据交换的最小单位。MESI协议将cache line的状态分成modify、exclusive、shared、invalid,分别是修改、独占、共享和失效。
- modify:当前 CPU cache 拥有最新数据(最新的 cache line),其他 CPU 拥有失效数据(cache line 的状态是 invalid),虽然当前 CPU 中的数据和主存是不一致的,但是以当前 CPU 的数据为准;
- exclusive:只有当前 CPU 中有数据,其他 CPU 中没有改数据,当前 CPU 的数据和主存中的数据是一致的;
- shared:当前 CPU 和其他 CPU 中都有共同数据,并且和主存中的数据一致;
- invalid:当前 CPU 中的数据失效,数据应该从主存中获取,其他 CPU 中可能有数据也可能无数据,当前 CPU 中的数据和主存被认为是不一致的;对于 invalid 而言,在 MESI 协议中采取的是写失效(write invalidate)。
M(Modified) 和 E(Exclusive) 状态的Cache line,数据是独有的,不同点在于M状态的数据是dirty的 (和内存的不一致),E状态的数据是clean的 (和内存的一致)。
S(Shared) 状态的Cache line,数据和其他Core的Cache共享。只有clean的数据才能被多个Cache共享。
I(Invalid)表示这个Cache line无效。
下面一一展示上上面说的状态图:
E 状态示例如下: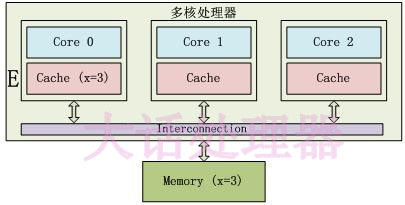
只有 Core 0 访问变量 x,它的 Cache line 状态为 E(Exclusive)。
S 状态示例如下: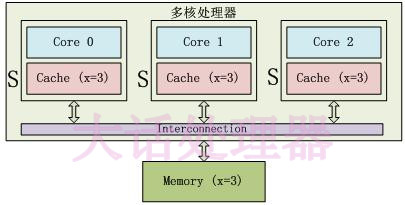
S 状态:3 个 Core 都访问变量 x,它们对应的 Cache line 为 S(Shared) 状态。
M 状态和 I 状态示例如下:
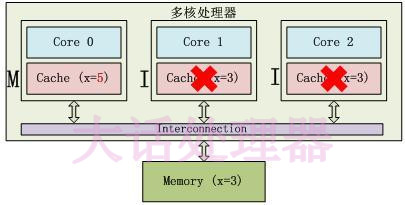
Core0修改了x的值之后,这个Cache line变成了M(Modified)状态,其他Core对应的Cache line变成了I(Invalid) 状态。
cache写操作
MESI协议中,每个cache的控制器不仅知道自己的操作(local read 和 local write),每个核心的缓存控制器通过监听也知道其他CPU中cache的操作(remote read 和 remote write),再确定自己cache中共享数据的状态是否需要调整。
- local read(LR:读本地 cache 中的数据;
- local write(LW):将数据写到本地 cache;
- remote read(RR):其他核心发生 read;
- remote write(RW):其他核心发生 write;
cache 状态转移
在MESI协议中,每个Cache的Cache控制器不仅知道自己的读写操作,而且也监听 (snoop) 其它Cache的读写操作。每个 Cache line所处的状态根据本核和其它核的读写操作在4个状态间进行迁移。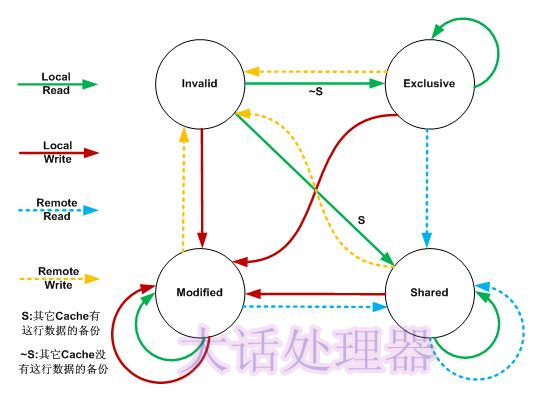
在上图中,Local Read表示本内核读本Cache中的值,Local Write表示本内核写本Cache中的值,Remote Read表示其它内核读其它Cache中的值,Remote Write表示其它内核写其它Cache中的值,箭头表示本Cache line状态的迁移,环形箭头表示状态不变。
当内核需要访问的数据不在本Cache中,而其它Cache有这份数据的备份时,本Cache既可以从内存中导入数据,也可以从其它Cache中导入数据,不同的处理器会有不同的选择。MESI协议为了使自己更加通用,没有定义这些细节,只定义了状态之间的迁移,下面的描述假设本 Cache 从内存中导入数据。
AMD 的 Opteron 处理器使用从 MESI 中演化出的 MOESI 协议,O(Owned) 是 MESI 中 S 和 M 的一个合体,表示本 Cache line 被修改,和内存中的数据不一致,不过其它的核可以有这份数据的拷贝,状态为 S。
Intel 的 core i7 处理器使用从 MESI 中演化出的 MESIF 协议,F(Forward) 从 Share 中演化而来,一个 Cache line 如果是 Forward 状态,它可以把数据直接传给其它内核的 Cache,而 Share 则不能。