开发人员在配置数据库连接池的时候,经常会犯一些错误。在配置数据库连接池时,需要理解一些可能违反直觉的原则。
因此本篇文章主要介绍这些原则。
10000前端用户同时访问
假设你有一个网站,虽然不像Facebook这样大的用户规模,但仍然有10000个用户同时发出数据库请求—每秒处理大约20000个事务。您的连接池应该有多大?你可能会惊讶于这个问题不是多大而是多小!
观看Oracle Real World Performance Group的这段简短视频,进行一次令人大开眼界的演示:
councurrent mid-tier connections
从视频中可以看出,在没有任何其他更改的情况下,仅减少连接池的大小就可以将应用程序的响应时间从平均100s缩短到2s,这是50倍以上的改进。
原因
最近,我们似乎已经在计算机领域的其他部分了解到,越少越好。为什么一个nginx web服务器只有4个线程,就可以在性能上超过一个包含100个进程的apache web服务器?如果你学过Computer Science 101,就会发现很明显是这样?
即使只有一个CPU核心的计算机也可以“同时”支持几十或数百个线程。但我们都应该知道,这仅仅是操作系统的一个小把戏,是通过time-slicing来实现的。实际上,单核一次只能执行一个线程;然后操作系统切换上下文,该核为另一个线程执行代码,依此类推。在给定单个CPU资源的情况下,通过time-slicing,顺序执行A和B总是比“同时”执行A和B更快,这是计算的基本规律。一旦线程的数量超过了CPU核心的数量,那么通过添加更多的线程(而不是更快的线程)会使速度变慢。
这几乎是对的……
有限的资源
这并不像上面所说的那么简单,但很接近。还有其他一些因素在起作用。当我们看到数据库的主要瓶颈是什么时,它们可以概括为三个基本类别:CPU、磁盘、网络。我们可以在其中添加内存,但是对比磁盘和网络,内存和磁盘、网络的带宽是有几个数量级的差异。
如果我们忽略了磁盘和网络,就很简单了。在具有8个计算核心的服务器上,将连接数设置为8将提供最佳性能,超出此范围的任何操作都将由于上下文切换的开销而开始减慢。但我们不能忽视磁盘和网络。数据库通常将数据存储在磁盘上,磁盘通常由金属旋转板和安装在步进电机驱动臂上的读/写头组成。读/写头一次只能在一个位置(单个查询的读/写数据),并且必须“查找”到新位置才能读/写其他查询的数据。因此有一个寻道时间成本,也有一个旋转成本,磁盘必须等待数据在盘中“再次出现”,以便读取/写入。缓存在这里当然有帮助,但这一原则仍然适用。
在此期间(“I/O等待”),连接/查询/线程只是“阻塞”等待磁盘。在此期间,操作系统可以通过为另一个线程执行更多的代码来更好地利用CPU资源。因此,由于线程在I/O上被阻塞,我们实际上可以通过拥有比物理计算颜色更多的连接/线程来完成更多的工作。
大小设置多少?我们下面会给出解释。设置连接数的多少还取决于磁盘子系统,因为较新的SSD驱动器没有“寻道时间”成本或旋转因素来处理。不要被欺骗向下面这样去想“固态硬盘更快,因此我可以有更多的线程”。真实的情况和这是180度的大反转。更快、无寻道、无旋转延迟意味着更少的阻塞,因此更少的线程[接近核心计数]比更多的线程性能更好。更多线程只有在阻塞创建执行机会时才能更好地执行。(也就是有更多的阻塞发生时)。
Network is similar to disk. Writing data out over the wire, through the ethernet interface, can also introduce blocking when the send/receive buffers fill up and stall. A 10-Gig interface is going to stall less than Gigabit ethernet, which will stall less than a 100-megabit. But network is a 3rd place runner in terms of resource blocking and some people often omit it from their calculations.
网络类似于磁盘。通过以太网接口在线路上写数据,当发送/接收缓冲区填满和停止时也可以在导致阻塞产生。一个10Gig的接口将比1Gig以太网慢,而千兆位以太网将比100兆位慢。但在资源阻塞方面,网络排名第三,有些人经常在计算中忽略它。
下面有张图来总结上面的文字。
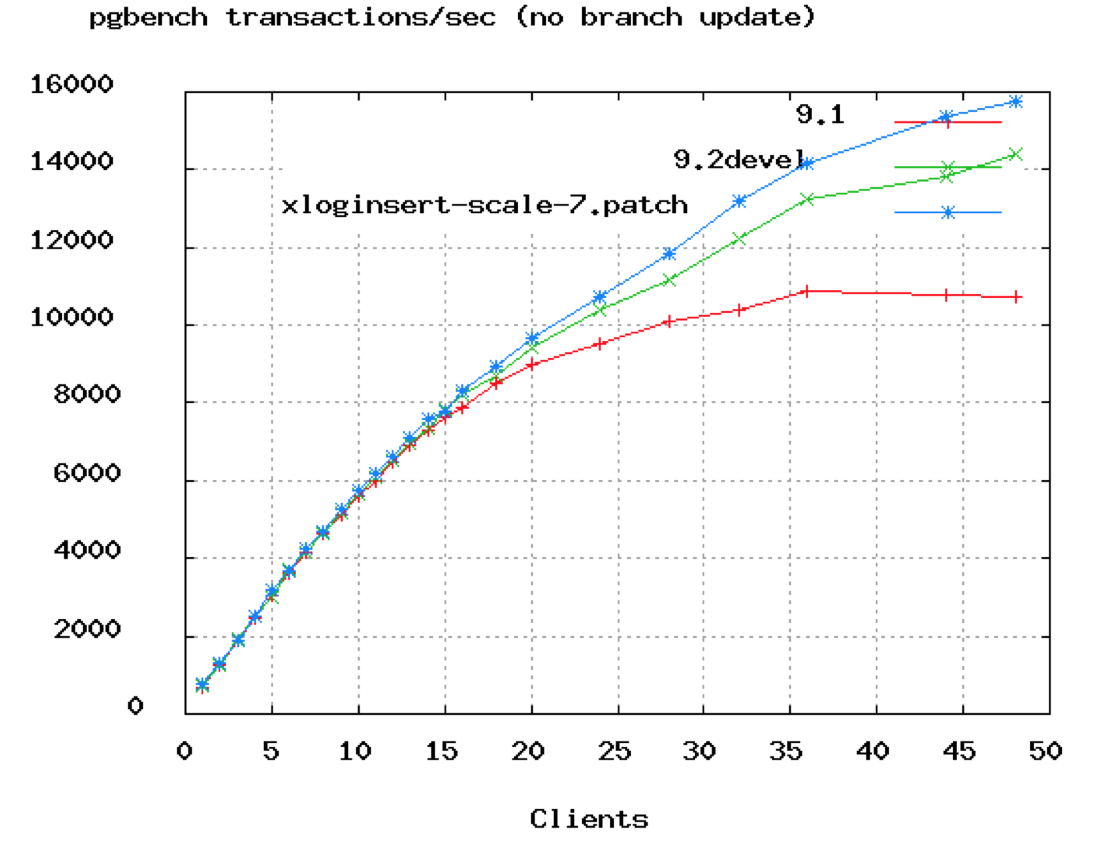
您可以在上面的PostgreSQL基准中看到,TPS速率在大约50个连接处开始变平。在上面的甲骨文视频中,他们展示了将连接从2048降到96.我们可以看到,即使96个可能也太高了,除非你看一个16或32核的cpu。
公式
下面的公式是由PostgreSQL项目提供的,作为一个起点,但是我们相信它在很大程度上可以跨数据库应用。您应该测试您的应用程序,即模拟预期的负载,并在此起点周围尝试不同的池设置:
1 | connections = ((core_count * 2) + effective_spindle_count) |
这个公式多年来在很多基准上都表现得很好。因此为了获得最佳吞吐量,活动连接数的设置应该参考上面的公式。Core count不应包括HT线程,即使启用了超线程。如果活动数据集被完全缓存,effective_spindle_count应该是0。接近实际effective_spindle_count数当缓存命中率下降时…到目前为止还没有关于这个公式在固态硬盘上的使用效果如何。
猜猜上面公式是什么意思?带有一个硬盘的4核i7服务器应该运行一个连接池:9=(4*2)+1)。把它称为10是一个很好的整数。看起来很低?试一试,我们敢打赌,在这样的设置下,您可以轻松地处理3000个运行6000 tps简单查询的前端用户。如果您运行负载测试,您可能会看到TPS速率开始下降,前端响应时间开始上升,因为您将连接池推得远远超过10(在给定的硬件上)。
公理:您需要一个小池,其中充满了等待连接的线程。
如果您有10000个前端用户,那么拥有10000个连接池就太疯狂了。1000个仍然很可怕。即使是100个连接,也会造成过度破坏。您最多需要一个包含几十个连接的小池,并且您希望池中的其余应用程序线程被阻塞,等待连接。如果对池进行了正确的调优,则将其设置在数据库能够同时处理的查询数的限制范围内——这很少超过(CPU核心*2),如上所述。
我们从未停止过对所遇到的内部web应用程序的惊叹,其中只有几十个前端用户执行定期活动,连接池中有100个连接。不要过度配置数据库。
池锁定
对于获得许多连接的单个参与者,“池锁定”的前景已经被提出。这在很大程度上是一个应用程序级的问题。是的,增加池大小可以减轻这些场景中的锁定,但是我们建议您首先检查在应用程序级别可以做什么,然后再扩大池。
为了避免死锁,计算池大小是一个相当简单的资源分配公式:
1 | pool size = Tn x (Cm - 1) + 1 |
其中tn是最大线程数,cm是单个线程同时保持的最大连接数。
例如,假设有三个线程(tn=3),每个线程需要四个连接来执行某些任务(cm=4)。确保永远不可能发生死锁所需的池大小是:
1 | pool size = 3 x (4 - 1) + 1 = 10 |
另一个例子是,最多有八个线程(tn=8),每个线程需要三个连接来执行某些任务(cm=3)。确保永远不可能发生死锁所需的池大小是:
1 | pool size = 8 x (3 - 1) + 1 = 17 |
这不一定是最佳池大小,而是避免死锁所需的最小值。
在某些环境中,使用JTA(Java事务管理器)可以极大地减少将从getConnection()返回相同的连接所需的连接数量到已经在当前事务中保持连接的线程。
提醒
池大小最终是非常特定于部署的。
例如,混合了长时间运行事务和非常短事务的系统通常最难与任何连接池进行调优。在这些情况下,创建两个池实例可以很好地工作(例如,一个用于长时间运行的作业,另一个用于“实时”查询)。
在主要具有长时间运行事务的系统中,通常对所需的连接数有一个“外部”约束——例如一个只允许同时运行一定数量的作业的作业执行队列。在这些情况下,作业队列大小应该是“正确的大小”,以匹配池(而不是相反)。