本文翻译自Zuul 2 : The Netflix Journey to Asynchronous, Non-Blocking Systems
前面在学习Spring Cloud中,了解到zuul这个应用网关,但是由于当时看到的是zuul1,使用的Servlet方式实现,所以整体性能很低。不过Netflix实际上升级了zuul,使用了netty来改造网关,也就是现在网关底层使用的是异步非阻塞的架构。下面我们就一起来拜读下他们的改造路程。
翻译如下:
我们最近对我们的云网关Zuul进行了重大架构改造。Zuul2的功能与其前任相同 - 作为Netflix服务器基础设施的前门,处理来自全球所有Netflix用户的流量。它还可以路由请求,支持开发人员的测试和调试,深入了解我们的整体服务运行状况,保护Netflix免受攻击,并在AWS区域出现问题时将流量引导至其他云区域。 Zuul 2和原始版本之间的主要架构差异是Zuul2使用Netty在异步和非阻塞框架上运行。在过去几个月投入生产之后,主要优势(我们在开始这项工作时所期望的一个优势)是它为设备和Web浏览器提供了在Netflix规模上持久连接回Netflix的能力。拥有超过8300万会员,每个会员都有多个连接设备,这是一个巨大的挑战。通过与我们的云基础架构保持持久连接,我们可以实现许多有趣的产品功能和创新,减少整体设备请求,提高设备性能,更好地理解和调试客户体验。
我们还希望Zuul2在延迟,吞吐量和成本方面提供弹性优势和性能改进。但正如您将在本文中了解到的那样,我们的愿望与结果不同。
阻塞和非阻塞系统的不同之处
要理解为什么我们构建Zuul2,您必须首先理解异步非阻塞(异步)系统与多线程阻塞(阻塞)系统之间的架构差异,无论是在理论上还是在实践中。
Zuul1构建于Servlet框架之上。这样的系统是阻塞和多线程的,这意味着它们通过每个连接使用一个线程来处理请求。I/O操作的完成是通过从线程池中选择I/O工作线程执行,并且阻塞请求线程直到工作线程完成。工作线程在其工作完成时通知请求线程。这适用于处理100个并发连接的现代多核AWS实例。但是当出现问题时,如后端延迟增加或设备因错误而重试,活动连接和线程的数量会增加。当发生这种情况时,节点会遇到麻烦,并且可能会陷入死亡螺旋,其中备份线程会加剧服务器负载并使群集不堪重负。为了抵消这些风险,我们建立了限流机制和库(例如,Hystrix)帮助我们的阻塞系统在这些事件中保持稳定。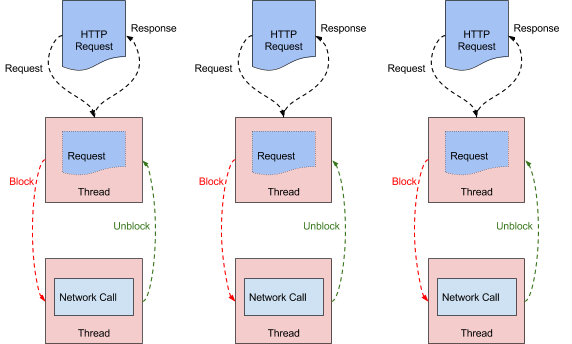
异步系统的运行方式不同,通常每个CPU核心只有一个线程处理所有请求和响应。请求和响应的生命周期通过事件和回调来处理。因为不是一个请求对应一个线程,所以连接成本很低。这里成本消耗都只是文件描述符以及监听器的添加。而阻塞模型中的连接成本是一个线程,并且具有大量内存和系统开销。并且这里一个线程处理所有的请求和响应会带来下面的好处。由于数据保留在同一CPU上,因此可以更好地利用CPU级别缓存并减少上下文切换,从而提高效率。后端延迟和重试风暴(客户和设备在发生问题时重试请求)的影响对系统的压力也较小,因为队列中的连接和事件的增加远比堆积线程要便宜。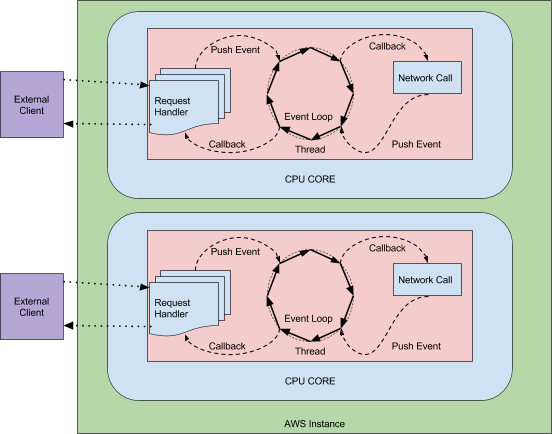
与同步阻塞的处理机制不同,Async是基于回调并由事件循环驱动的。尝试跟踪请求时,事件循环的堆栈跟踪毫无意义。在处理事件和回调时很难跟踪请求,并且在这方面非常缺乏帮助调试它的工具。边缘情况,未处理的异常和错误处理的状态更改会产生悬空资源(什么是悬空资源,可以参考文后给出的野指针和悬空指针的文章链接),导致ByteBuf泄漏,文件描述符泄漏,丢失响应等。这些类型的问题已经证明很难调试,因为很难知道哪个事件没有妥善处理或适当清理。
构建非阻塞zuul
在Netflix的基础设施内构建Zuul2比预期更具挑战性。Netflix生态系统中的许多服务都是在假设阻塞的情况下构建的。Netflix的核心网络库也采用阻塞架构假设下构建的;许多库依赖线程局部变量来构建和存储有关请求的上下文。因为异步非阻塞的架构是在同一线程上处理多个请求,所以线程局部变量在异步非阻塞世界中不起作用。因此,构建Zuul2的大部分复杂性在于解决使用线程局部变量的黑暗角落。其他挑战包括将阻塞网络逻辑转换为非阻塞网络代码,在库内部查找阻塞代码,修复资源泄漏以及将核心基础结构转换为异步运行。没有一种通用的策略可以将阻塞网络逻辑转换为异步;必须对它们进行单独分析和重构。这同样适用于核心Netflix库,其中一些代码被修改,一些代码必须分叉和重构以使用异步。通过检测我们的服务器以发现代码块和库被阻塞的情况,开源项目Reactive-Audit非常有用。
我们采用了一种有趣的方法来构建Zuul2.因为阻塞系统可以裕兴异步代码,所以我们首先更改我们的Zuul Filters和过滤器链路代码以异步运行。Zuul过滤器包含我们为执行网关功能而创建的特定逻辑(路由,日志记录,反向代理,ddos预防等)。我们使用RxJava重构核心Zuul,基本Zuul过滤器类和我们的Zuul过滤器,以允许它们异步运行。我们现在有两种类型的过滤器一起使用:用于异步的I/O操作,以及运行不需要I/ O逻辑操作的同步过滤器。 Async Zuul Filters允许我们在阻塞系统和非阻塞系统中执行完全相同的过滤器逻辑。这给我们一个能能力,可以使用一个过滤器集,以便我们可以为合作伙伴开发网关功能,同时在单个代码库中开发基于Netty的体系结构。随着异步Zuul过滤器逐步被取代,构建Zuul2就变成了让我们的Zuul基础架构的剩下部分以异步和非阻塞方式运行。相同的Zuul过滤器可能会落入两种架构中。
zuul2 在生产环境下的结果
假设与我们的网关的异步架构的好处差异很大。有些人认为,由于上下文切换的减少和CPU缓存的更有效使用,我们会看到效率提高一个数量级,而另一些人则认为我们根本没有看到效率增益。关于变革和发展努力的复杂性,意见也各不相同。
那么我们通过这种架构变化获得了什么?它值得吗?这个话题引起了激烈的争论。 Cloud Gateway团队率先在Netflix上创建和测试基于异步的服务。很有兴趣了解使用异步的微服务如何在Netflix上运行,而Zuul看起来像是看到好处的理想服务。
虽然我们没有看到迁移到异步和非阻塞的显着效率优势,但我们确实实现了连接扩展的目标。 Zuul确实受益于大大降低网络连接的成本,这将实现与设备之间的推送和双向通信。这些功能将实现更多实时用户体验创新,并通过推送通知替换当今(占据API流量的很大一部分)的“聊天”设备协议,从而降低整体云成本。与阻塞模型相比,在原始系统处理重试风暴和延迟方面也有一些弹性优势。我们正在继续改善这一领域;然而,应该指出的是,弹性优势并非直截了当或没有努力和调整。
由于能够将Zuul的核心业务逻辑放入阻塞或异步架构,我们对阻塞与异步比较进行了有趣的比较。那么,两个系统如何以完全不同的方式完成相同的实际工作,在功能,性能和弹性方面进行比较?在过去的几个月中运行Zuul2后,我们的评估是系统如果是对cpu依赖越大(cpu-bound:cpu密集型),我们看到的效率增益就越小。
我们有几个不同的Zuul集群,它们是前端服务,如API,回放,网站和日志记录。每个源服务都要求相应的Zuul集群处理不同的操作。例如,支持我们的API服务的Zuul集群可以完成我们所有集群的最多工作,包括度量计算,日志记录和解密传入的有效负载以及压缩响应。我们认为从一个异步的zuul2转换到阻塞的网关不会获得有效的收益。从容量和CPU的角度来看,它们本质上是等价的,考虑到Zuul服务前端API的CPU密集程度,这是有意义的。它们也倾向于每个节点大约相同的吞吐量情况下降级。
我们的日志服务前端的Zuul群集具有不同的性能评测。Zuul通常从设备接收日志记录和分析消息,并且写入很多,因此请求很大,但响应很小,而且Zuul没有加密。因此,Zuul为这个集群做的工作少得多。虽然仍然受CPU限制,但通过运行基于Netty的Zuul,我们看到吞吐量增加了25%,相当于CPU利用率降低了25%。因此,我们观察到系统实际执行的工作越少,我们从异步中获得的效率就越高。
总体而言,我们从这种架构变化中获得的价值很高,连接扩展是主要的好处,但它确实需要付出代价。我们的系统在调试,编码和测试方面要复杂得多,而且我们在Netflix的一个生态系统中工作,该系统在假设阻塞系统的情况下运行。生态系统不太可能很快发生变化,因此当我们向网关添加和集成更多功能时,我们可能需要继续梳理线程局部变量以及客户端库和其他支持代码中阻塞的其他假设。我们还需要异步重写阻塞调用。这是一个独特的工程挑战,可以使用完善的平台和代码体来进行阻塞。在绿地中(未开发过的,原始)构建和集成Zuul2可以避免一些复杂性,但我们在这样的环境中运行,这些库和服务对于Netflix生态系统中的网关和操作功能至关重要。
我们正在将Zuul2作为开源发布。一旦发布,我们很乐意听取您的使用经验,并希望您能分享您的贡献!我们计划为Zuul2添加http2和websocket支持等新功能,以便社区也可以从这些创新中受益。