这篇分析 doCreateBean() 第三个过程:循环依赖处理。其实循环依赖并不仅仅只是在 doCreateBean() 中处理,其实在整个加载 bean 的过程中都有涉及,所以下篇内容并不仅仅只局限于 doCreateBean(),而是从整个 Bean 的加载过程进行分析。
什么是循环依赖
循环依赖其实就是循环引用,就是两个或者两个以上的 bean 互相引用对方,最终形成一个闭环,如 A 依赖 B,B 依赖 C,C 依赖 A,如下:
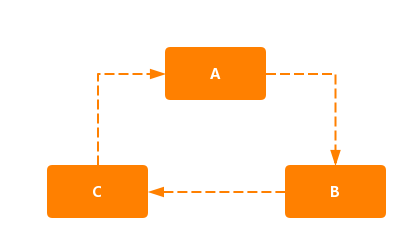
循环依赖其实就是一个死循环的过程,在初始化A的时候发现引用了B,这时就会去初始化B,然后又发现B引用C,跑去初始化 C,初始化 C 的时候发现引用了 A,则又会去初始化 A,依次循环永不退出,除非有终结条件。
Spring 循环依赖的场景有两种:
- 构造器的循环依赖
- field属性的循环依赖
对于构造器的循环依赖,Spring是无法解决的,只能抛出BeanCurrentlyInCreationException异常表示循环依赖,所以下面我们分析的都是基于 field 属性的循环依赖。
Spring 只解决 scope 为 singleton 的循环依赖,对于scope 为 prototype 的 bean Spring 无法解决,直接抛出 BeanCurrentlyInCreationException 异常。为什么 Spring 不处理 prototype bean,其实如果理解 Spring 是如何解决 singleton bean 的循环依赖就明白了。这里先卖一个关子,我们先来关注 Spring 是如何解决 singleton bean 的循环依赖的。
解决循环依赖
我们先从加载 bean 最初始的方法 doGetBean() 开始。
在 doGetBean() 中,首先会根据 beanName 从单例 bean 缓存中获取,如果不为空则直接返回。
1 | Object sharedInstance = getSingleton(beanName); |
调用 getSingleton() 方法从单例缓存中获取,如下:
1 | protected Object getSingleton(String beanName, boolean allowEarlyReference) { |
这个方法主要是从三个缓存中获取,分别是:singletonObjects、earlySingletonObjects、singletonFactories,三者定义如下:
1 | /** Cache of singleton objects: bean name --> bean instance */ |
意义如下:
- singletonObjects:单例对象的cache
- singletonFactories : 单例对象工厂的cache
- earlySingletonObjects :提前暴光的单例对象的Cache
他们就是Spring解决singleton bean的关键因素所在,我称他们为三级缓存,第一级为singletonObjects,第二级为earlySingletonObjects,第三级为singletonFactories。这里我们可以通过 getSingleton() 看到他们是如何配合的,这分析该方法之前,提下其中的isSingletonCurrentlyInCreation()和allowEarlyReference。
isSingletonCurrentlyInCreation():判断当前singleton bean 是否处于创建中。bean处于创建中也就是说bean在初始化但是没有完成初始化,前面我们在从缓存从获取单例对象也提到过这个方法。这样的过程其实和Spring解决bean循环依赖的理念相辅相成,因为Spring解决singleton bean的核心就在于提前曝光bean。- allowEarlyReference:从字面意思上面理解就是允许提前拿到引用。其实真正的意思是是否允许从singletonFactories缓存中通过
getObject()拿到对象,为什么会有这样一个字段呢?原因就在于 singletonFactories才是Spring解决singleton bean的诀窍所在,这个我们后续分析。
getSingleton()整个过程如下:首先从一级缓存singletonObjects获取,如果没有且当前指定的beanName正在创建,就再从二级缓存中earlySingletonObjects获取,如果还是没有获取到且运行singletonFactories 通过 getObject() 获取,则从三级缓存 singletonFactories 获取,如果获取到则通过其 getObject() 获取对象,并将其加入到二级缓存 earlySingletonObjects 中 从三级缓存 singletonFactories 删除,如下:
1 | singletonObject = singletonFactory.getObject(); |
这样就从三级缓存升级到二级缓存了。
上面是从缓存中获取,但是缓存中的数据从哪里添加进来的呢?一直往下跟会发现在 doCreateBean() ( AbstractAutowireCapableBeanFactory ) 中,有这么一段代码:
1 | boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences |
如果earlySingletonExposure == true的话,则调用addSingletonFactory()将他们添加到缓存中,但是一个bean要具备如下条件才会添加至缓存中:
- 单例
- 运行提前暴露bean
- 当前bean正在创建中
经过上面分析,我们了解添加addSingletonFactory满足什么条件才能调用,但是调用addSingletonFactory起到什么作用呢,我们还是以最简单AB循环依赖为例,类A中含有属性类B,类B中又含有属性A,那么初始化BeanA的过程入下图
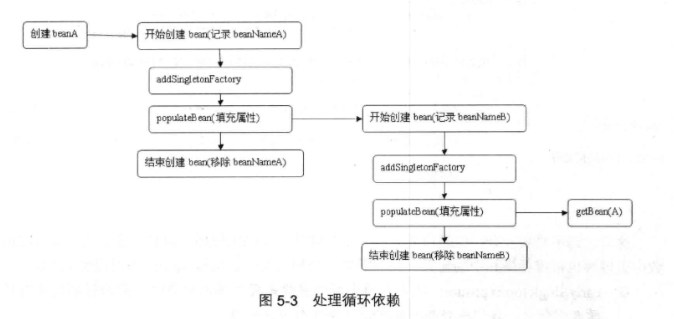

addSingletonFactory() 代码如下:
1 | protected void addSingletonFactory(String beanName, |
从这段代码我们可以看出singletonFactories这个三级缓存才是解决 Spring Bean 循环依赖的诀窍所在。同时这段代码发生在createBeanInstance()方法之后,也就是说这个bean其实已经被创建出来了,但是它还不是很完美(没有进行属性填充和初始化),但是对于其他依赖它的对象而言已经足够了(可以根据对象引用定位到堆中对象),能够被认出来了,所以Spring在这个时候选择将该对象提前曝光出来让大家认识认识。
getEarlyBeanReference如下
1 | protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) { |

介绍到这里我们发现三级缓存singletonFactories和二级缓存 earlySingletonObjects 中的值都有出处了,那一级缓存在哪里设置的呢?在类 DefaultSingletonBeanRegistry 中可以发现这个 addSingleton() 方法,源码如下:
1 | protected void addSingleton(String beanName, Object singletonObject) { |
添加至一级缓存,同时从二级、三级缓存中删除。这个方法在我们创建bean的链路中有哪个地方引用呢?其实在前面博客已经提到过了,在doGetBean()处理不同scope时,如果是singleton,则调用getSingleton(),如下:
1 | public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) { |
至此,Spring 关于 singleton bean 循环依赖已经分析完毕了。所以我们基本上可以确定 Spring 解决循环依赖的方案了:Spring在创建bean的时候并不是等它完全完成,而是在创建过程中将创建中的bean 的ObjectFactory提前曝光(即加入到singletonFactories缓存中),这样一旦下一个bean创建的时候需要依赖bean ,则直接使用ObjectFactory的getObject()获取了,也就是getSingleton()中的代码片段了。
到这里,关于 Spring 解决 bean 循环依赖就已经分析完毕了。最后来描述下就上面那个循环依赖 Spring 解决的过程:首先A完成初始化第一步并将自己提前曝光出来(通过 ObjectFactory 将自己提前曝光),在初始化的时候,发现自己依赖对象B,此时就会去尝试get(B),这个时候发现 B 还没有被创建出来,然后B就走创建流程,在 B 初始化的时候,同样发现自己依赖 C,C也没有被创建出来,这个时候C又开始初始化进程,但是在初始化的过程中发现自己依赖A,于是尝试 get(A),这个时候由于A已经添加至缓存中(一般都是添加至三级缓存singletonFactories ),通过 ObjectFactory提前曝光,所以可以通过 ObjectFactory.getObject() 拿到A对象,C拿到A对象后顺利完成初始化,然后将自己添加到一级缓存中,回到B ,B也可以拿到C对象,完成初始化,A可以顺利拿到B 完成初始化。到这里整个链路就已经完成了初始化过程了。
通过上面的介绍,你或与已经明白了,为什么Prototype scope范围内的bean不处理循环依赖,是因为这种类型的bean不能缓存,也就不能提前曝光,所以也就没有办法成功创建其中任何一个bean,就无法打破这个环。