本篇文章将要介绍的是ParNew和CMS搭配使用的垃圾回收器组合。CMS和其他老年代收集器不同的地点是,它使用的是标记-清除算法。
CMS收集器设计的目的是避免在老年代收集时长时间停顿。它通过两种方式实现这一目标。首先,它不是采用标记-拷贝来回收老年代,而是使用可被回收链表来管理回收空间。其次,整个垃圾回收器的执行期间,绝大部分是可以和应用程序并发执行。这意味着垃圾收器不会显式停止应用程序线程执行来执行。但是应该注意,它仍然与应用程序线程竞争CPU时间。默认情况下,此GC算法使用的线程数等于计算机物理核心数的1/4。
如果您的主要目标是延迟,这种组合在多核机器上是一个不错的选择。减少单个GC暂停的持续时间会直接影响终端用户使用应用程序的感受,从而使他们感觉应用程序响应更快。由于大多数时候GC消耗了一些CPU资源而没有执行应用程序的代码,因此CMS垃圾回收器通常比只运行Parallel GC的垃圾回收器的吞吐量要差一些。
正文
如果想要使用这中搭配方式,需要在运行java程序时使用下面参数:
1 | -XX:+UseParNewGC - -XX:+UseConcMarkSweepGC |
测试代码如下:
1 | /************************************** |
输出日志信息如下:
1 | 2019-04-18T15:38:27.114+0800: 0.112: [GC (Allocation Failure) 2019-04-18T15:38:27.114+0800: 0.112: [ParNew: 5640K->376K(9216K), 0.0099638 secs] 5640K->4474K(19456K), 0.0100193 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] |
年轻代(Minor GC)
日志信息如下:
1 | 2019-04-18T15:38:27.114+0800: 0.112: [GC (Allocation Failure) 2019-04-18T15:38:27.114+0800: 0.112: [ParNew: 5640K->376K(9216K), 0.0099638 secs] 5640K->4474K(19456K), 0.0100193 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] |
按照显示的顺序来进行介绍:
2019-04-18T15:38:27.114+0800:GC开始的时间0.112:GC开始相对于JVM启动的开始时间,单位是秒GC:标记用于辨别是年轻代GC还是Full GC(回收年轻代和老年代)Allocation Failure:造成GC的原因。在这个案例里,GC被启动的原因是年轻代所剩的空间不能满足对象的分配。ParNew:GC回收器使用的名称。这里代表ParNew垃圾回收器。5640K->376K(9216K): GC回收前年轻代使用的空间大小->GC回收后年轻代使用的空间大小(年轻代总空间大小)0.0099638 secs:收集持续的时间,还没有最终的清理5640K->4474K(19456K):GC前堆已被使用的空间大小->GC后堆中已被使用的空间大小(堆可被使用的总大小)0.0100193 secs:整个GC持续的时间,标记和复制年轻代活着的对象所花费的时间(包括和老年代通信的开销、对象晋升到老年代开销、垃圾收集周期结束一些最后的清理对象等的花销)[Times: user=0.00 sys=0.00, real=0.00 secs]:参照前面的文章这里就不具体解释
老年代
下面是CMS垃圾回收器的日志,这些是按照CMS的不同阶段打印出来:
1 | 2019-04-18T15:38:27.141+0800: 0.139: [GC (CMS Initial Mark) [1 CMS-initial-mark: 7487K(10240K)] 13833K(19456K), 0.0002405 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] |
下面分别来介绍各个阶段的情况:
阶段1:Initial Mark
这个是 CMS 两次 stop-the-wolrd 事件的其中一次,这个阶段的目标是:标记那些直接被 GC root 引用或者被年轻代存活对象所引用的所有对象,标记后示例如下所示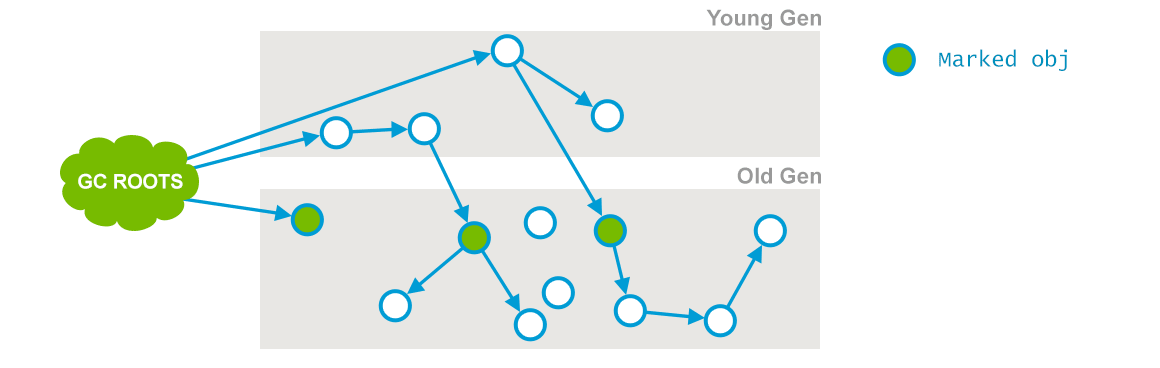
上述例子对应的日志信息为:
1 | 2019-04-18T15:38:27.141+0800: 0.139: [GC (CMS Initial Mark) [1 CMS-initial-mark: 7487K(10240K)] 13833K(19456K), 0.0002405 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] |
日志的意思如下:
2019-04-18T15:38:27.141+0800:0.139:GC 开始的时间,以及相对于 JVM 启动的相对时间(单位是秒,这里大概是4.33h),与前面 ParNew 类似,下面的分析中就直接跳过这个了;CMS-initial-mark:初始标记阶段,它会收集所有 GC Roots 以及其直接引用的对象;7487K:当前老年代使用的容量;(10240k):老年代可用的最大容量,这里是 10M;13833K:整个堆目前使用的容量;(19456K):堆可用的容量,这里是19M;0.0002405 secs:这个阶段的持续时间;[Times: user=0.04 sys=0.00, real=0.04 secs]:与前面的类似,这里是相应 user、system and real 的时间统计。
阶段2 concurrent Mark
在这个阶段GC垃圾回收器会遍历老年代,然后标记所有存活的对象,它会根据上个阶段找到的 GC Roots 遍历查找。并发标记阶段,它会与用户的应用程序并发运行。并不是老年代所有的存活对象都会被标记,因为在标记期间用户的程序可能会改变一些引用,如下图所示: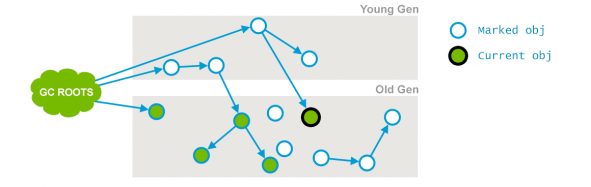
在上面的图中,与阶段1的图进行对比,就会发现有一个对象的引用已经发生了变化,这个阶段相应的日志信息如下:
1 | 2019-04-18T15:38:27.141+0800: 0.139: [CMS-concurrent-mark-start] |
CMS-concurrent-mark:并发收集阶段,这个阶段会遍历老年代,并标记所有存活的对象;0.000/0.000 secs:这个阶段的持续时间与时钟时间;[Times: user=0.00 sys=0.00, real=0.00 secs]:如前面所示,但是这部分的时间,其实意义不大,因为它是从并发标记的开始时间开始计算,这期间因为是并发进行,不仅仅包含 GC 线程的工作,还包括了应用线程并行的线程。
阶段3:concurrent Preclean
Concurrent Preclean:这也是一个并发阶段,与应用的线程并发运行,并不会stop应用的线程。上面一个阶段和应用并发运行的过程中,一些对象的引用可能会发生变化,但是这种情况发生时,JVM会将包含这个对象的区域(Card)标记为 Dirty,这也就是 Card Marking。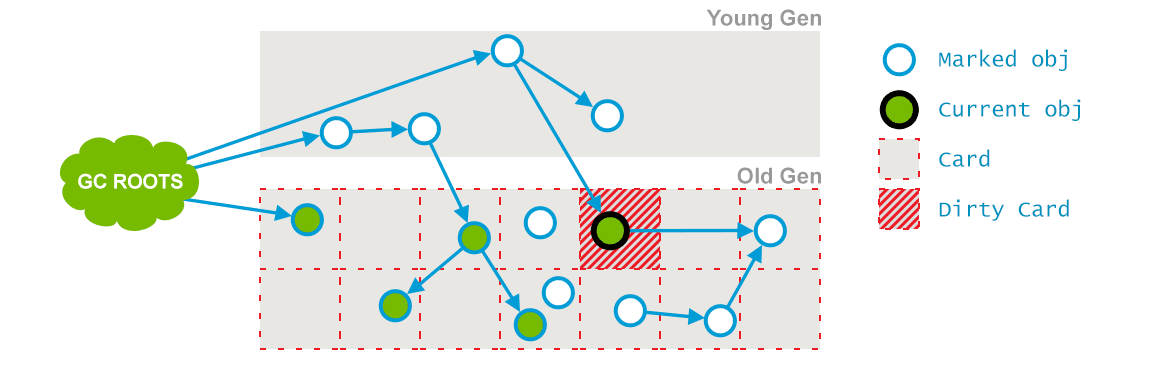
在pre-clean阶段,那些能够从 Dirty 对象到达的对象也会被标记,这个标记做完之后,dirty card 标记就会被清除了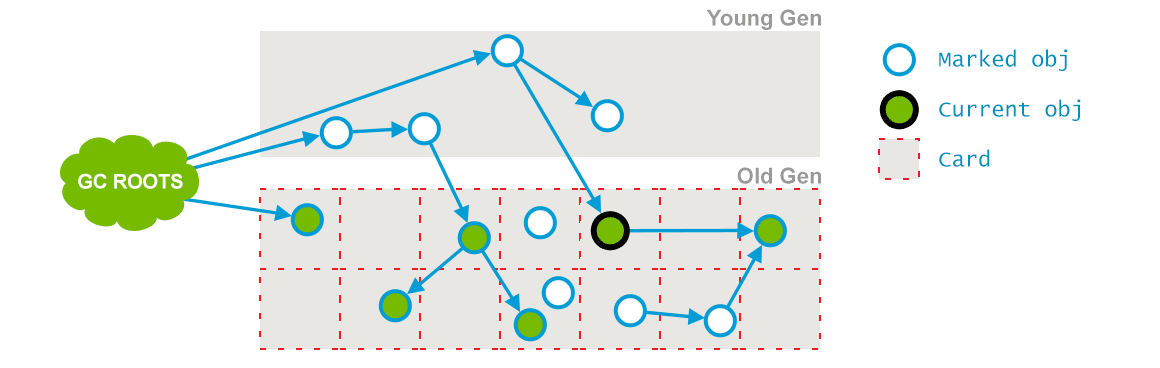
1 | 2019-04-18T15:38:27.141+0800: 0.139: [CMS-concurrent-preclean-start] |
CMS-concurrent-preclean:Concurrent Preclean阶段,对在前面并发标记阶段中引用发生变化的对象进行标记;0.000/0.000 secs:这个阶段的持续时间与时钟时间;[Times: user=0.00 sys=0.00, real=0.00 secs]:同并发标记阶段中的含义。
阶段4:Concurrent Abortable Preclean
这也是一个并发阶段,同样不会影响影响用户的应用线程。这个阶段是为了尽量承担最终标记阶段的工作(这个阶段会STW)。这个阶段持续时间依赖于很多的因素。这个阶段是在重复做很多相同的工作,直到满足一些条件(比如:重复迭代的次数、完成的工作量或者时钟时间等)就会退出。这个阶段的日志信息如下:
1 | 2019-04-18T15:38:27.142+0800: 0.139: [CMS-concurrent-abortable-preclean-start] |
CMS-concurrent-abortable-preclean:Concurrent Abortable Preclean 阶段;0.000/0.000 secs:这个阶段的持续时间与时钟时间,本质上,这里的 gc 线程会在 STW 之前做更多的工作,通常会持续 5s 左右;[Times: user=0.00 sys=0.00, real=0.00 secs]:同前面。
阶段5:Final Remark
这是第二个 STW 阶段,也是 CMS 中的最后一个,这个阶段的目标是标记所有老年代所有的存活对象,由于之前的阶段是并发执行的,gc线程可能跟不上应用程序的变化,为了完成标记老年代所有存活对象的目标,STW就非常有必要了。
通常 CMS的Final Remark 阶段会在年轻代尽可能干净的时候运行,目的是为了减少连续STW发生的可能性(年轻代存活对象过多的话,也会导致老年代涉及的存活对象会很多)。这个阶段会比前面的几个阶段更复杂一些,相关日志如下:
1 | 2019-04-18T15:38:27.142+0800: 0.140: [GC (CMS Final Remark) [YG occupancy: 6345 K (9216 K)]2019-04-18T15:38:27.142+0800: 0.140: [Rescan (parallel) , 0.0006864 secs]2019-04-18T15:38:27.142+0800: 0.140: [weak refs processing, 0.0001303 secs]2019-04-18T15:38:27.142+0800: 0.140: [class unloading, 0.0003487 secs]2019-04-18T15:38:27.143+0800: 0.141: [scrub symbol table, 0.0003745 secs]2019-04-18T15:38:27.143+0800: 0.141: [scrub string table, 0.0002689 secs][1 CMS-remark: 7487K(10240K)] 13833K(19456K), 0.0019541 secs] [Times: user=0.01 sys=0.00, real=0.00 secs] |
2019-04-18T15:38:27.142+0800: 0.140:阶段开始的时间,阶段开始的时间相对与JVM启动的时间,单位s[GC (CMS Final Remark):表示这是CMS的Final Remark阶段[YG occupancy: 6345 K (9216 K)]:年轻代当前占内存大小,及年轻代总的内存大小2019-04-18T15:38:27.142+0800: 0.140: [Rescan (parallel) , 0.0006864 secs]:前面的时间表示的是这个阶段开始的时间,和相对JVM启动的时间。Rescan 是当应用暂停的情况下完成对所有存活对象的标记,这个阶段是并行处理的,这里花费了 0.0006864s;2019-04-18T15:38:27.142+0800: 0.140: [weak refs processing, 0.0001303 secs]:前面的时间表示的是这个阶段开始的时间,和相对JVM启动的时间。第一个子阶段,它的工作是处理弱引用;后面是这个阶段花费的时间2019-04-18T15:38:27.142+0800: 0.140: [class unloading, 0.0003487 secs]:前面的时间表示的是这个阶段开始的时间,和相对JVM启动的时间。第二个子阶段,它的工作是卸载为被使用的类,后面是这个阶段花费的时间2019-04-18T15:38:27.143+0800: 0.141: [scrub symbol table, 0.0003745 secs]:前面时间表示的是这个阶段开始的时间和相对JVM启动的开始时间。第三个子阶段,清理符号表,包含了类级元数据。寿面时间表示这个阶段花费的时间。2019-04-18T15:38:27.143+0800: 0.141: [scrub string table, 0.0002689 secs]:前面时间表示的是这个阶段开始的时间和相对JVM启动的开始时间,这是最后的子阶段,清理字符串表,内部化字符串。后面时间表示这个阶段花费的时间。还包括暂停的时钟时间。[1 CMS-remark: 7487K(10240K)] 13833K(19456K), 0.0019541 secs]这个阶段之后,老年代堆的使用情况(老年代总的内存大小)堆的使用量与总量(包括年轻代,年轻代在前面发生过 GC)[Times: user=0.01 sys=0.00, real=0.00 secs]:在不同态下执行的时间。
经历过这五个阶段之后,老年代所有存活的对象都被标记过了,现在可以通过清除算法去清理那些老年代不再使用的对象。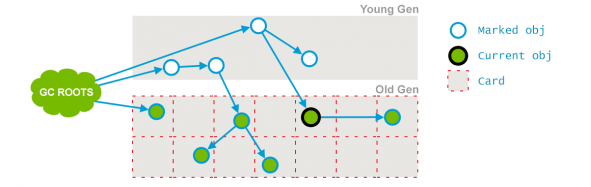
阶段6:Concurrent Sweep
这里不需要STW,它是与用户的应用程序并发运行,这个阶段是:清除那些不再使用的对象,回收它们的占用空间为将来使用。如下图所示
1 | 2019-04-18T15:38:27.144+0800: 0.142: [CMS-concurrent-sweep-start] |
CMS-concurrent-sweep:这个阶段主要是清除那些没有被标记的对象,回收它们的占用空间;0.000/0.000 secs:这个阶段的持续时间与时钟时间;[Times: user=0.00 sys=0.00, real=0.00 secs]:同前面;
阶段7:Concurrent Reset
这个阶段也是并发执行的,它会重设 CMS 内部的数据结构,为下次的 GC 做准备,对应的日志信息如下:
1 | 2019-04-18T15:38:27.144+0800: 0.142: [CMS-concurrent-reset-start] |
日志详情分别如下:
CMS-concurrent-reset:这个阶段的开始,目的如前面所述;0.000/0.000 secs:这个阶段的持续时间与时钟时间;Times: user=0.15 sys=0.10, real=0.04 secs]:同前面。
总结
CMS通过将大量工作分散到并发处理阶段来在减少STW时间,在这块做得非常优秀,但是CMS也有一些其他的问题,具体的可以看这篇文章JVM垃圾回收器:
- CMS 收集器无法处理浮动垃圾( Floating Garbage),可能出现 “Concurrnet Mode Failure” 失败而导致另一次 Full GC 的产生,可能引发串行Full GC;
- 空间碎片,导致无法分配大对象,CMS 收集器提供了一个 -XX:+UseCMSCompactAtFullCollection 开关参数(默认就是开启的),用于在 CMS 收集器顶不住要进行 Full GC 时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长;
- 对于堆比较大的应用上,GC 的时间难以预估。