可以参考这俩篇文章,还未来得急整理
guava之RateLimiter限流原理解析
Mysql是如何执行查询
本篇文章会按照以下思路来对mysql查询的原理进行讲解,首先讲解mysql是如何在单表上执行查询,在此基础上,讲解多表查询的原理,也就是join时,mysql是如何执行查询的,最后讲解mysql是如何计算查询的成本。
Innodb索引深入研究
之前对索引这块有所了解,也按照一些索引优化实践对表进行过优化,但都是一知半解,不清楚为什么要这么做。本篇文章会对Innodb索引是怎么存储以及怎么使用的进行深入的研究,从而理解索引优化的原理,最后会对索引的使用进行总结。
索引存储结构
先来看下Innodb是如何存储数据。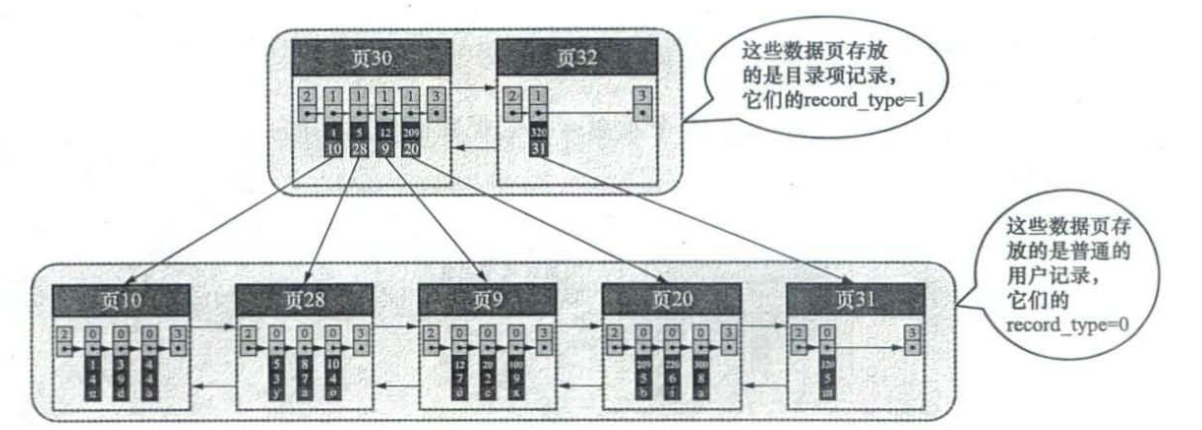
从上图可以看出,最下层存储的是相关的记录,上面一层存储的是目录项,其实就是主键索引。目录项存储格式和存储真实记录的格式一样,具体的行格式可以参考InnoDB行格式,只不过是存储的内容不一样,目录项存储的内容是主键值和其对应的页号。
通过目录项就可以根据主键id快速找到对应的记录,具体的查找过程如下
- 确定存储主键id对应的目录页
- 通过存储目录项记录的页确定用户记录真正所在的页
- 在真正存储用户记录的页中定位到具体的记录
另外在Innodb中,每个数据页的大小是16KB,上面存储目录的页和存储数据的页都叫做数据页,因此每页能存储的目录项是确定的,当超出大小时,就会产生一个新的目录页来存储对应的目录。最终会产生出下面这种样式的存储结构,类似于多级目录,大的目录页里嵌套小的目录页。存储数据的页当超出能存储的最大数据记录个数时,也会创建一个新的页面存储,但是只会在最下面一层。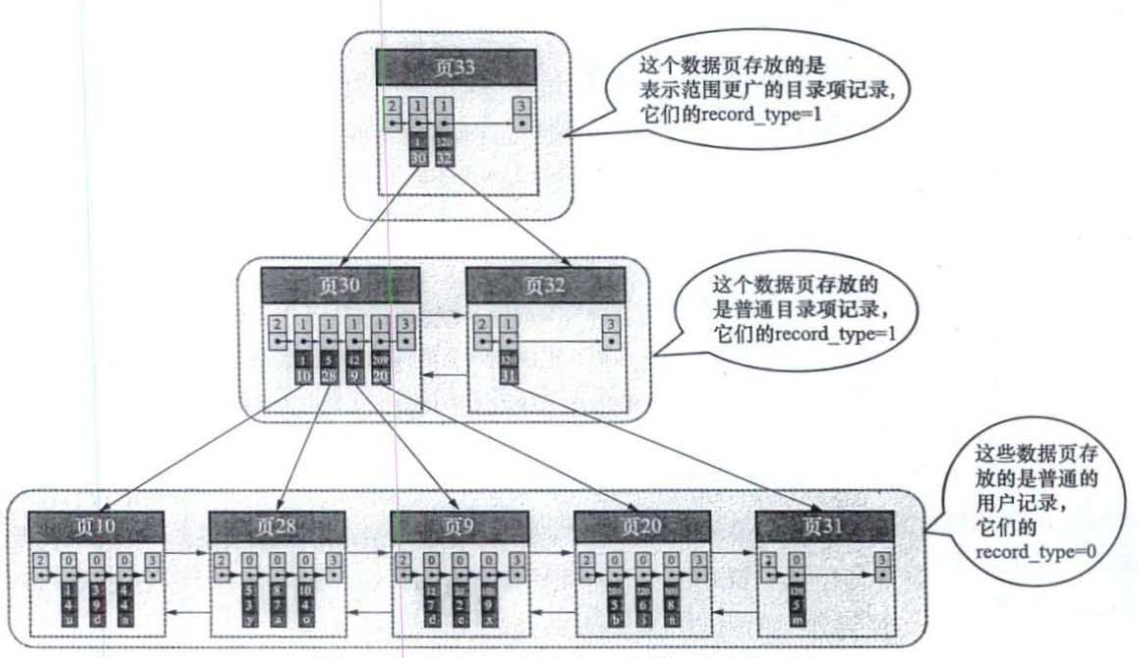
上面描述的结构其实就是B+树。具体什么是B+树介绍的文章比较多,这里就不在具体阐述,只需要明白Innodb是如何存储数据的即可。
下面介绍几个概念
- 聚簇索引: 数据和索引存储在一块,上面描述的主键索引就是聚簇索引。
- 二级索引: 非主键索引以外的索引都可以叫做二级索引,这种索引和主键索引存储结构是一样,只是记录的数据有区别,在目录项中记录的是二级索引对应的列、主键以及页地址,数据记录中记录的是列值和主键值。因此当使用二级索引查找数据时,仅仅只是找到了对应的主键值,还需要根据主键值在主键索引中查找对应的数据,级回表操作。
- 联合索引: 多列组合在一起的索引,也属于二级索引,区别是存储多个列。
索引优缺点
索引的优点当然是能够加速查找,缺点有俩点,空间: 创建一个新的索引,就会将对应的结构存储到磁盘上,会增加存储的代价。时间: 虽然索引能够增加查询的速度,但是对于增删改操作时,不仅需要完成操作本身,还需要操作对应的索引,因此会增加相应的时间成本。
应用索引
参考
- Mysql是怎样运行的
Innodb 索引结构是怎样的
使用索引带来的问题
虚拟IP和路由漂移
Innodb行格式
InnoDB是mysql数据库中最常用的存储引擎,对其底层进行研究有助于理解常见的一些数据库优化思路。本篇文章介绍一条记录是如何存储在磁盘上。
我们平时都是以记录为单位向表中插入数据的,这些记录在磁盘上的存放形式也被称为行格式或者记录格式。InnoDB存储引擎到现在为止设计了4种不同类型的行格式,
分别是COMPACT、REDUNDANT、DYNAMI、COMPRESSED。其中REDUNDANT是最早使用的数据格式,现在基本上不怎么使用。目前使用较多的是其它三种格式,这三种格式基本相似,只在处理变长字段上有不同。下文将首先介绍COMPACT格式,然后在以此对比来说明另外俩种格式。
分布式事务之本地事务表和事务消息
在一些业务场景中,对于数据的强一致性并不是严格要求。比如用户购买商品时增加用户的积分,对于用户来说,重要的是下单成功,至于增加积分相对不是非常重要,在一段时间内保证用户的积分增加成功即可。对于这类场景,可以使用最终一致性的方案,带来的好处是可以增加应用的可用性以及qps。
本文介绍实现最终一致性的俩种方案,本地事务表和事务消息,俩种方案的核心思想都是将一个大事务拆分长一系列的小事务,通过重试机制保证一致性。
本地事务表 (An Acid Alternative)
本文翻译自Base: An Acid Alternative。
在分区数据库中,用一致性换取可用性可以显著提高可伸缩性。
Web应用程序在过去十年中越来越流行。无论您是为终端用户还是为应用程序开发人员(服务)构建应用程序,您最希望的是您的应用程序将获得广泛采用,并且随着广泛采用,将带来事务性增长。如果应用程序依赖持久性,那么数据存储可能会成为瓶颈。
有两种策略可以扩展任何应用程序。第一个,也是迄今为止最简单的,是垂直扩展:将应用程序移动到更大的计算机上。垂直缩放对数据的效果相当好,但有几个限制。最明显的限制是超出了最大系统的容量。垂直扩展也很昂贵,因为增加事务处理能力通常需要购买下一个更大的系统。垂直扩展通常会造成供应商锁定,进一步增加成本。
水平缩放提供了更大的灵活性,但也相当复杂。水平数据缩放可以沿两个方向执行。功能扩展涉及按功能对数据进行分组,并将功能组分布在数据库中。将功能区域内的数据跨多个数据库拆分,或进行切分,即第二种策略。下图解释了水平数据缩放策略。
seata简单总结
快速生成测试数据
日常在写单元测试过程中,如何构造合适的测试数据是比较麻烦并且乏味的。本篇将介绍俩个工具用于生成测试数据,首先介绍Datafaker,此工具用于生成各种常见的测试数据。接着介绍easy-random,用于生成测试对象。最后介绍如何结合这俩个工具生成比较真实的测试对象。