JVM内存区域之逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术,它与类型继承关系分析一样,并不是直接优化代码的手段,而是为其他优化措施提供依据的分析技术。
逃逸分析的基本原理是:分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸;甚至还有可能被外部线程访 问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸;从不逃逸、方法逃逸到线程逃逸,称为对象由低到高的不同逃逸程度。
如果能证明一个对象不会逃逸到方法或线程之外(换句话说是别的方法或线程无法通过任何途径 访问到这个对象),或者逃逸程度比较低(只逃逸出方法而不会逃逸出线程),则可能为这个对象实例采取不同程度的优化,
- 栈上分配(Stack Allocations):在Java虚拟机中,Java堆上分配创建对象的内存空间几乎是Java程序员都知道的常识,Java堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问到堆中存储的对象数据。虚拟机的垃圾收集子系统会回收堆中不再使用的对象,但回收动作无论是标记筛选出可回收对象,还是回收和整理内存,都需要耗费大量资源。如果确定一个对象不会逃逸出线程之外,那让这个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,完全不会逃逸的局部对象和不会逃逸出线程的对象所占的比例是很大的,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集子系统的压力将会下降很多。栈上分配可以支持方法逃逸,但不能支持线程逃逸。
- 标量替换(Scalar Replacement):若一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型(int、long等数值类型及reference类型等)都不能再进一步分解了,那么这些数据就可以被称为标量。相对的,如果一个数据可以继续分解,那它就被称为聚合量(Aggregate),Java中的对象就是典型的聚合量。如果把一个Java对象拆散,根据程序访问的情况,将其用到的成员变量 恢复为原始类型来访问,这个过程就称为标量替换。假如逃逸分析能够证明一个对象不会被方法外部访问,并且这个对象可以被拆散,那么程序真正执行的时候将可能不去创建这个对象,而改为直接创 建它的若干个被这个方法使用的成员变量来代替。将对象拆分后,除了可以让对象的成员变量在栈上 (栈上存储的数据,很大机会被虚拟机分配至物理机器的高速寄存器中存储)分配和读写之外,还可 以为后续进一步的优化手段创建条件。标量替换可以视作栈上分配的一种特例,实现更简单(不用考 虑整个对象完整结构的分配),但对逃逸程度的要求更高,它不允许对象逃逸出方法范围内。
- 同步消除(Synchronization Elimination):线程同步本身是一个相对耗时的过程,如果逃逸分析 能够确定一个变量不会逃逸出线程,无法被其他线程访问,那么这个变量的读写肯定就不会有竞争, 对这个变量实施的同步措施也就可以安全地消除掉。
关于逃逸分析的研究论文早在1999年就已经发表,但直到JDK 6,HotSpot才开始支持初步的逃逸分析,而且到现在这项优化技术尚未足够成熟,仍有很大的改进余地。不成熟的原因主要是逃逸分析的计算成本非常高,甚至不能保证逃逸分析带来的性能收益会高于它的消耗。如果要百分之百准确地判断一个对象是否会逃逸,需要进行一系列复杂的数据流敏感的过程间分析,才能确定程序各个分支执行时对此对象的影响。前面介绍即时编译、提前编译优劣势时提到了过程间分析这种大压力的分析 算法正是即时编译的弱项。可以试想一下,如果逃逸分析完毕后发现几乎找不到几个不逃逸的对象, 那这些运行期耗用的时间就白白浪费了,所以目前虚拟机只能采用不那么准确,但时间压力相对较小 的算法来完成分析。
从测试结果来看,实施逃逸分析后的程序在MicroBenchmarks中往往能得到不错的成绩,但是在实际的应用程序中,尤其是大型程序中反而发现实施逃逸分析可能出现效果不稳定的情况,或分析过程 耗时但却无法有效判别出非逃逸对象而导致性能(即时编译的收益)下降,所以曾经在很长的一段时 间里,即使是服务端编译器,也默认不开启逃逸分析,甚至在某些版本(如JDK 6 Update 18)中还曾经完全禁止了这项优化,一直到JDK 7时这项优化才成为服务端编译器默认开启的选项。如果有需要,或者确认对程序运行有益,用户也可以使用参数-XX:+DoEscapeAnalysis来手动开启逃逸分析, 开启之后可以通过参数-XX:+PrintEscapeAnalysis来查看分析结果。有了逃逸分析支持之后,用户可以使用参数-XX:+EliminateAllocations来开启标量替换,使用+XX:+EliminateLocks来开启同步消除,使用参数-XX:+PrintEliminateAllocations查看标量的替换情况。 尽管目前逃逸分析技术仍在发展之中,未完全成熟,但它是即时编译器优化技术的一个重要前进 方向,在日后的Java虚拟机中,逃逸分析技术肯定会支撑起一系列更实用、有效的优化技术。
参考
JVM内存区域之虚拟机栈
Spring注解@Autoired和@Resource区别对比
Hibernate Validator 学习与使用
Hibernate Validator 学习与使用
在项目,校验数据是必不可少的一步。因此如果能写出一个好的校验代码,必定能提高项目的鲁棒性。目前我做的项目大部分使用的是SpringBoot,基本上都是在控制器那一层通过注解@Valid等来校验参数,虽然经常使用,但是没有好好的进行整理。所以接下来会写几篇文章,对这一块进行整理。
大概会整理如下几个部分
- Hibernate Validator的用法,
- 如何在Spring中使用Hibernate Validator
- 介绍如何在Spring MVC中使用。
- 分析Spring MVC使用Validator的原理。
本篇文章主要是对Hibernate Validator用法进行简单的介绍
Hibernate Validator简介
验证数据是贯穿所有应用程序层(从应用层到持久层)的常见任务。通常在每一层都实现相同的验证逻辑,这是非常耗时和容易出错的。为了避免这些验证的重复,开发人员经常将验证逻辑直接绑定到域模型中,用验证代码(实际上是关于类本身的元数据)将域类弄乱。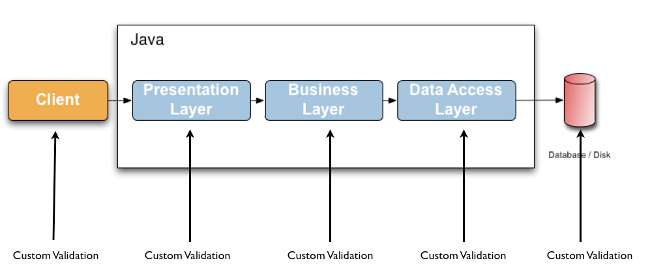
Jakarta Bean Validation 2.0——为Entity和方法的验证定义了一个元数据模型和API。默认的元数据源是Annotation,同时也能够通过使用XML覆盖和扩展元数据。API没有绑定到特定的应用层或者programming model.。它与web层或持久层都没有强绑定,可用于服务器端应用程序编程和客户端上应用程序。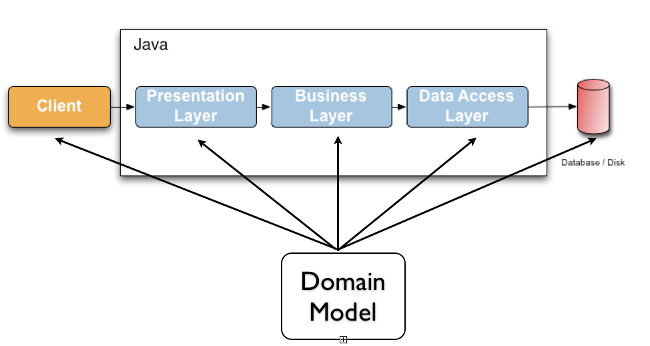
Hibernate Validator和Jakarta Bean Validation的区别:Jakarta Bean Validation是一种规范,Hibernate Validator是对个规范的一种实现。
URL详解
Spring Validation教程
Spring Validation教程
前面已经有俩篇文章介绍了Hibernate Validator的使用,而Spring Validation就是对Hibernate Validator又一层封装,方便在Spring中使用。这里我们先介绍Spring Validation的基本用法,包含在Service层中使用和在Controller中使用。
在Spring中有俩种校验Bean的方式,一种是通过实现org.springframework.validation.Validator接口,然后在代码中调用这个类,另外一种是按照Bean Validation方式来进行校验,即通过注解的方式,这一种和前面介绍的使用Hibernate Validator来进行校验基本一致。
MapStruct使用教程一
MapStruct使用教程一
在日常开发中,我们会定义多种不通的Javabean,比如DTO(Data Transfer Object:数据传输对象),DO(Data Object:数据库映射对象,与数据库一一映射),VO(View Object:显示层对象,通常是 Web 向模板渲染引擎层传输的对象)等等这些对象。在这些对象与对象之间转换通常是调对象的set和get方法进行复制,这种转换通常也是很无聊的操作,因此就需要有一个专门的工具来解决Javabean之间的转换问题,让我们从这种无聊的转换操作中解放出来。
MapStruct就是这样一个属性映射工具,用于解决上述对象之间转换问题。MapStruct官网。官网给出的MapStruct定义:MapStruct是一个Java注释处理器,用于生成类型安全的bean映射类。
我们要做的就是定义一个映射器接口,声明任何必需的映射方法。在编译的过程中,MapStruct会生成此接口的实现。该实现使用纯java方法调用的源对象和目标对象之间的映射。对比手写这些映射方法,MapStruct通过自动生成代码完成繁琐和手写容易出错的代码逻辑从而节省编码时间。遵循配置方法上的约定,MapStruct使用合理的默认值,但在配置或实现特殊行为时不加理会。
与动态映射框架相比,MapStruct具有以下优点:
- 速度快:使用普通的方法代替反射
- 编译时类型安全性 : 只能映射彼此的对象和属性,不会将商品实体意外映射到用户DTO等
- 在build时期有明确的错误报告,主要有下面俩种
- 映射不完整,目标对象中有些属性没有被映射
- 映射不正确,找不到一个合适的映射方法或者类型转换方法
如何从Jar包中加载class
之前在看java类加载机制的时候,就在想,JVM是如何在Jar包中找到某个具体的Class文件,如果是把Jar包解压到一个指定的文件中,那我还能理解,他是先解压然后在去解压后的文件中查找有没有具体的文件,但事实上,jvm在运行java程序时候,并没有将jar包解压。所以就比较好奇jvm是如何获取到具体的class文件。本篇文章主要对其进行探究。