前文介绍过TCP是一种可靠的协议,主要通过超时重传管理、窗口管理、流量控制、拥塞控制来保证其可靠性。本文将对这些概念进行详细介绍,主要分文三大部分,重传,流量控制,拥塞控制。
重传
经过N多专家前扑后继的研究,在目前的信息论(information theory)和编码理论(coding theory)中,主要有两种方式用来保证可靠的传输
通过传输的数据包中增加冗余的error-correcting codes来修复传出错误的报文,这种方式中接受端在接收到报文的时候,如果报文中有少量的bit传输错误,接收端可以通过冗余数据恢复出正确的数据包。
使用ARQ(Automatic Repeat Request)机制来提高数据传输的可靠性,ARQ机制需要发送端重复发送传输错误的数据包直到接收端接收到正确的数据包为止
解决丢包和比特错误两类问题最简单的方式就是重新发送出错的数据包,TCP协议使用的是这种方式,但是这也带来俩个问题:
- 接收端是否已经接收到对应的数据包:这个可以通过ACK(acknowledgment)机制来确认接收端接收到数据包的情况。但是这个又带来其他小问题比如发送端应该等待ACK确认包多长时间?如果超过这个时间发送端就认为数据包丢失而重新发送这个数据包,这个时间在TCP协议中叫做RTO(Retransmission Timeout),后面会详细介绍。
- 接收端接收到的数据包和发送端发送的数据包是否一致:一般来说有两种方式,一种是CRC,另外一种是checksum,在TCP协议中通过checksum机制检查比特错误。当TCP的checksum校验失败的时候,接收端并不会发送ACK给发送端。对于数据完整性要求较高的应用,应该在应用层添加更可靠的校验方式。
在TCP协议中有俩种形式的重传,一种是基于定时机制的重传,一种是快重传,下面将对这俩种重传机制进行详细介绍,这里补充一点在这重传内容中我们重点关注TCP如果判断丢包以及重传对应的数据包。至于发送多少数据包则等到我们后面的拥塞控制时候在来讲解。
基于定时机制重传
这种机制是指对于发送出去的报文,如果没有在指定时间内进行确认,就重传报文。这个指定的时间在前面也介绍了,叫做RTO,RTO是根据环回时间RTT(round-trip-time)来估计。环回时间应该包括三部分:数据包传送到接收端的时间,接收端处理这个数据包并产生ACK的时间,ACK确认包返回到发送端的时间。但是RTT这个时间是随着网络状况动态变化的,网络负载较重产生拥塞的时候,RTT就会变大,因此发送端就需要一种方式来动态估计这个RTT时间,这个过程就叫做round-trip-time estimation。这个估计过程是一个统计过程,真实的RTT应该比较接近这个统计平均值。所以基于定时机制重传的重要地点就是计算RTO。
这里有一点需要注意是对每个连接维护一个超时定时器,而不是对每个发出去的TCP报文。
RTO的计算主要分为俩部分,一部分是测量RTT,在TCP中叫做RTT采样(RTT sample) ,主要原理是TCP在接收到数据后会发送累计的ACK number,因此TCP发送某个系列号的报文后,在接收到覆盖此系列号的ACK报文的时候,测量发送和接收之间的时间。第二部分根据RTT采样得到的数据,采用算法计算RTO,协议中主要有两种方法来计算RTO一种是RFC793的经典方法(classic method),另一种是RFC6298的标准方法(standard method)。具体的计算过程这里就不介绍,有兴趣可以去协议官网查看。
RTO默认值是1S,得到了具体的RTO,下面来看下重传的具体步骤,也就是RTO定时器的管理,协议对于RTO定时器的建议管理方法如下:
- 每次一个包含数据的TCP报文发送出去的时候(包括重传),如果RTO定时器没有运行,则重启RTO定时器,并设置定时时间为RTO。
- 当所有发出的数据报文都被ACK后,关闭这个RTO定时器。
- 当一个新的ack number到达的时候(新的ack number是指ack了新数据),如果还有未被ACK的数据,则重启RTO定时器,并设置定时时间为当前RTO。
当RTO定时器触发的时候(即所设置的定时时间到达的时候)
- 在没有任何ACK的报文到达的情况下,重传最早发出去的报文。
- 设置RTO = RTO * 2,这也就是我们经常说的指数回退。这里可以设置一个上限来限制RTO大小。
- 重启RTO定时器,设置定时时间为RTO(这里的RTO是已经回退过的RTO)。
- 如果RTO定时器是因为等待SYN报文的ACK而超时,同时实现上使用的RTO值小于3s,这个RTO定时器必须被重新初始化为3s。
在重传完成后,新的RTT采样可能会将RTO设置为与原来比较接近的值,从而消除指数回退对于RTO的影响。另外在多次指数回退过程中,TCP实现可能会清空之前的一些记录值,会导致RTO需要一段时间才能恢复到一个合理的值,增加通信的时间。
快重传
基于ACK报文结构顺序的重传,这种重传叫做快速重传(fast retransmission或者fast retransmit),当TCP注意到累计ack(即TCP头中的ack number)不再推进或者接收端通过SACK信息指示发送端接收端存在洞(hole)时候就会触发发送端的重传。
通常来说快速重传比超时重传更高效。
按照TCP协议,RTO超时重传是一个非常重要的事件,当RTO超时的时候,TCP会同时通过两种方式非常谨慎的降低发送数据包的速率,一种是基于拥塞控制削减发送窗口的大
小,另外一个是通过指数回退增加每次RTO超时的时间(即karn算法的第二部分)。所以RTO超时后有可能会导致网络容量的利用不足。
快速重传是RFC5681定义一个的一个过程。快速重传不依赖定时器的超时,而是依靠ACK确认包来进行重传。使用快速重传相比RTO超时重传通常可以更高效的修复TCP丢包问题。快速重传是基于一个前提:即按照RFC5681,当TCP收到一个乱序报文的时候应该立即回复ACK确认包,而不会延迟ACK(延迟ACK:等待服务端有数据发送,将ACK和发送的数据结合在一起发送给客户端,从而介绍发送的次数)确认。另外RFC5681还指出如果接收序列号空间存在洞,新接收的报文完全填充了这个洞或者部分填充了这个洞,TCP也应该立即回复一个ACK确认包以便发送端及时获取接收端相关的信息。
我们举个例子来详细介绍基本的快速重传,假设有5个TCP报文,P1(1-10)、P2(11-20)、P3(21-30)、P4(31-40)、P5(41-50),其中括号中标注的是报文的比特系列号,每个报文的长度都为10bytes。假设发送端依次发送这5个报文,其中P2报文在网络传输过程中丢失,P1、P3、P4、P5报文依次按序到达,接收端收到这P1的时候发送ack=11的确认包(实际上这里可能会延迟发送ACK报文,为了描述简单我们假设立即发送ACK报文),接收端收到P3的时候发现是乱序的报文则会立即回复ack=11确认包(还记得ACK是累计确认的吧,因为P2丢失了ACK只能累计到11),同样后面收到P4和P5的时候还是会回复ack=11的确认包。这样发送端就会连续接收到4个ack=11的确认包,后面三个确认包因为和第一个ack number重复,称呼为duplicate ACK。发送端就可以依据dup ACK来推测接收端的接收情况。但是我们之前说过IP层不会向TCP提供有序的数据报文,如果网络传输过程中发生乱序导致接收端接收顺序变为P1、P3、P2、P4、P5,这样的情况下也会产生一个dup ACK。另外还有一种情况是IP层导致了dup ACK报文。我们通过一个dup ACK并不能可靠的确认是发生了丢包还是发生了乱序传输,因此会存在一个门限(duplicate ACK threshold或者叫做dupthresh),当TCP收到的dup ACK数超过这个门限的时候,就会认为发生了丢包,进而初始化一个快速重传。最初协议中给出的dupthresh这个上限是3,不同的操作系统可以调整这个值。在没有使能SACK的时候,快速重传只会重传一个数据包,在使能SACK时候,SACK可以反映接收端是否存在系列号洞,进而允许发送端根据SACK的情况同时传输多个数据包。
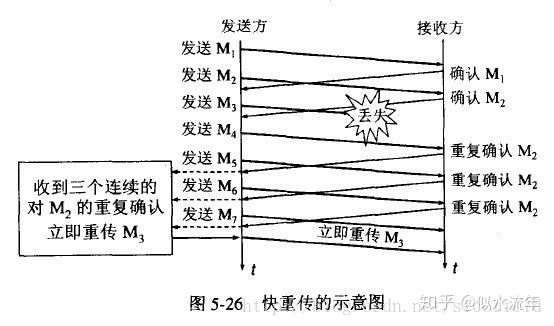
下面来详细说明下什么是SACK。SACK的全称是selective acknowledgment,也就是选择性确认,添加sack功能需要在TCP包头加两个选项,一个是开启选项(enabling option),另一个是sack选项(sack option)本身。开启sack选项后,接收者会将自己收到了哪些包,没收到哪些包的信息记录在sack段中告诉给发送方,这样发送方便可以一次性重传所有的丢包。
在早期的TCP拥塞控制中,通过收到duplicate ack(默认为3个),连续三次ack某一个包来告诉sender某个丢包了,然后进入fast retransmition state,发送方重传这个包,当接收方收到这个重传包后,便会发一个ack(ack新的包)给发送方,告诉发送方下一个要发送的包是哪一个。可以看到,通过duplicate ack每次只能重传一个包,如果有多个丢包,在等待重传过程中,很容易timeout,造成带宽利用率下降(underutilized)。
而如果开启sack,每一个sack段记录的是已经收到的连续的包,sack段与sack段之间断片的,也就是还没收到的(可能已经丢失,也可能是reorder)。通过sack段便可以知道多个可能已经丢失的包,这样便可以一次性的重传,而不是一个一个重传,避免因等待时间长造成的timeout问题。
另外注意就是SACK块是按照最新形成的洞信息倒序排列的。每个ACK报文中可以携带多个SACK块的原因是因为ACK确认包有可能会丢包,但是ACK报文不消耗系列号因此不会进行重传,因此接收端通过多个ACK报文中冗余的SACK块信息来提高SACK信息传输的可靠性。
开启sack选项,也是有弊端的,因为丢包意味着网络很可能已经拥塞,这时如果一次重传多个包,很可能会造成网络更加拥塞。
流量控制
什么是流量控制?流量控制的目的?
如果发送者发送数据过快,接收者来不及接收,那么就会有分组丢失。为了避免分组丢失,控制发送者的发送速度,使得接收者来得及接收,这就是流量控制。流量控制根本目的是防止分组丢失,它是构成TCP可靠性的一方面。
如何实现流量控制?
由滑动窗口协议(连续ARQ协议)实现。滑动窗口协议既保证了分组无差错、有序接收,也实现了流量控制。主要的方式就是接收方返回的 ACK 中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送。
滑动窗口
滑动窗口协议的基本原理就是在任意时刻,发送方都维持了一个连续的允许发送的帧的序号,称为发送窗口;同时,接收方也维持了一个连续的允许接收的帧的序号,称为接收窗口。发送窗口和接收窗口的序号的上下界不一定要一样,甚至大小也可以不同。不同的滑动窗口协议窗口大小一般不同。发送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧。
举例解释:
发送和接受方都会维护一个数据帧的序列,这个序列被称作窗口。发送方的窗口大小由接受方确定,目的在于控制发送速度,以免接受方的缓存不够大,而导致溢出,同时控制流量也可以避免网络拥塞。下面图中的4,5,6号数据帧已经被发送出去,但是未收到关联的ACK,7,8,9帧则是等待发送。可以看出发送端的窗口大小为6,这是由接受端告知的(事实上必须考虑拥塞窗口cwnd,这里暂且考虑cwnd>rwnd)。此时如果发送端收到4号ACK,则窗口的左边缘向右收缩,窗口的右边缘则向右扩展,此时窗口就向前滑动了,即数据帧10也可以被发送。
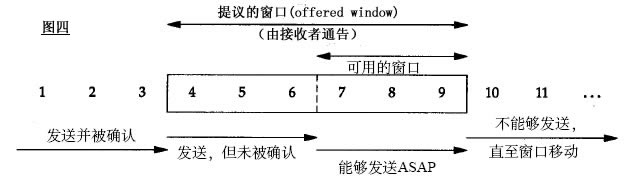
称窗口左边沿向右边沿靠近为窗口合拢。这种现象发生在数据被发送和确认时。
当窗口右边沿向右移动时将允许发送更多的数据,我们称之为窗口张开。这种现象发生在另一端的接收进程读取已经确认的数据并释放了T C P的接收缓存时。
当右边缘向左移动时,称之为窗口收缩。
注:cwnd(congestion window) 拥塞窗口的简写,rwnd(Receive Window)接收窗口
举例2:
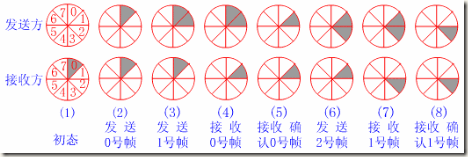
一:初始态,发送方没有帧发出,发送窗口前后沿相重合。接收方0号窗口打开,等待接收0号帧;
二:发送方打开0号窗口,表示已发出0帧但尚确认返回信息。 此时接收窗口状态不变;
三:发送方打开0、1号窗口,表示0、1号帧均在等待确认之列。至此,发送方打开的窗口数已达规定限度,在未收到新的确认返回帧之 前,发送方将暂停发送新的数据帧。接收窗口此时状态仍未变;
四:接收方已收到0号帧,0号窗口关闭,1号窗口打开,表示准备接收1号帧。此时发送窗口状态不 变;
五:发送方收到接收方发来的0号帧确认返回信息,关闭0号窗口,表示从重发表中删除0号帧。此时接收窗口状态仍不变
六:发送方继续发送2号帧,2号窗口 打开,表示2号帧也纳入待确认之列。至此,发送方打开的窗口又已达规定限度,在未收到新的确认返回帧之前,发送方将暂停发送新的数据帧,此时接收窗口状态 仍不变;
七:接收方已收到1号帧,1号窗口关闭,2号窗口打开,表示准备接收2号帧。此时发送窗口状态不变;
八:发送方收到接收方发来的1号帧收毕的确认信 息,关闭1号窗口,表示从重发表中删除1号帧。此时接收窗口状态仍不变。
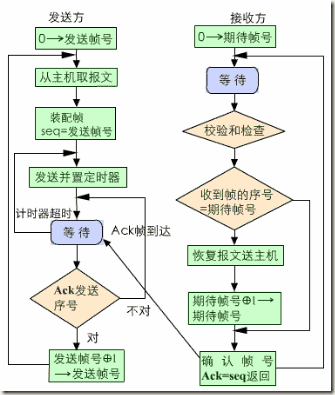
1比特滑动窗口协议
上面说的只是滑动窗口协议的理论,实际应用中又有不同。首先就是停等协议(stop-and-wait),这时接受方的窗口和发送方的窗口大小都是1,1个比特就够表示了,所以也叫1比特滑动窗口协议。发送方这时自然发送每次只能发送一个,并且必须等待这个数据包的ACK,才能发送下一个。虽然在效率上比较低,带宽利用率明显较低,不过在网络环境较差,或是带宽本身很低的情况下,还是适用的。看下面的流程图:
后退n协议
停等协议虽然实现简单,也能较好的适用恶劣的网络环境,但是显然效率太低。所以有了后退n协议,这也是滑动窗口协议真正的用处,这里发送的窗口大小为n,接受方的窗口仍然为1。具体看下面的图,这里假设n=9:
首先发送方一口气发送10个数据帧,前面两个帧正确返回了,数据帧2出现了错误,这时发送方被迫重新发送2-8这7个帧,接受方也必须丢弃之前接受的3-8这几个帧。
后退n协议的好处无疑是提高了效率,但是一旦网络情况糟糕,则会导致大量数据重发,反而不如上面的停等协议,实际上这是很常见的,具体可以参考TCP拥塞控制。
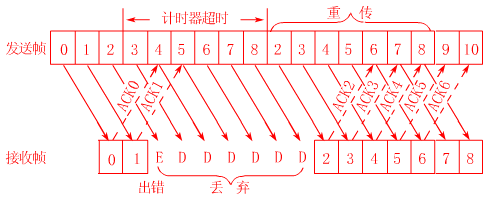
选择重传协议
后退n协议的另外一个问题是,当有错误帧出现后,总是要重发该帧之后的所有帧,毫无疑问在网络不是很好的情况下会进一步恶化网络状况,重传协议便是用来解决这个问题。原理也很简单,接收端总会缓存所有收到的帧,当某个帧出现错误时,只会要求重传这一个帧,只有当某个序号后的所有帧都正确收到后,才会一起提交给高层应用。重传协议的缺点在于接受端需要更多的缓存。
流量控制引发的死锁?怎么避免死锁的发生?
当发送者收到了一个窗口为0的应答,发送者便停止发送,等待接收者的下一个应答。但是如果这个窗口不为0的应答在传输过程丢失,发送者一直等待下去,而接收者以为发送者已经收到该应答,等待接收新数据,这样双方就相互等待,从而产生死锁。
为了避免流量控制引发的死锁,TCP使用了持续计时器。每当发送者收到一个零窗口的应答后就启动该计时器。时间一到便主动发送报文询问接收者的窗口大小。若接收者仍然返回零窗口,则重置该计时器继续等待;若窗口不为0,则表示应答报文丢失了,此时重置发送窗口后开始发送,这样就避免了死锁的产生。
拥塞控制
拥塞发生的主要原因在于网络能够提供的资源不足以满足用户的需求,这些资源包括缓存空间、链路带宽容量和中间节点的处理能力。由于互联网的设计机制导致其缺乏“接纳控制”能力,因此在网络资源不足时不能限制用户数量,而只能靠降低服务质量来继续为用户服务,也就是尽力而为的服务。
拥塞其实是一个动态问题,我们没有办法用一个静态方案去解决,从这个意义上来说,拥塞是不可避免的。
拥塞控制与流量控制的区别
拥塞控制:拥塞控制是作用于网络的,它是防止过多的数据注入到网络中,避免出现网络负载过大的情况;常用的方法就是:( 1 )慢开始、拥塞避免( 2 )快重传、快恢复。
流量控制:流量控制是作用于接收者的,它是控制发送者的发送速度从而使接收者来得及接收,防止分组丢失的。
下面分析拥塞控制核心算法
慢开始算法
当主机开始发送数据时,如果立即所大量数据字节注入到网络,那么就有可能引起网络拥塞,因为现在并不清楚网络的负荷情况。因此,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是说,由小到大逐渐增大拥塞窗口数值。通常在刚刚开始发送报文段时,先把拥塞窗口cwnd设置为一个最大报文段MSS的数值。即连接建好的开始先初始化cwnd = 1,表明可以传一个SMSS大小的数据。每当收到一个ACK,cwnd++; 呈线性上升。每当过了一个RTT,cwnd = cwnd*2; 呈指数让升。
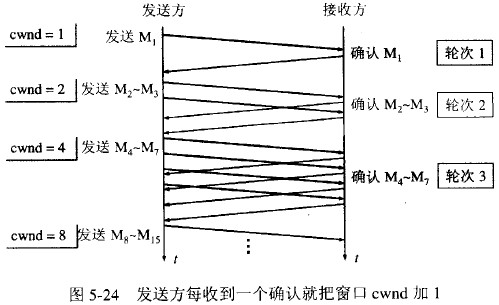
慢开始的慢并不是指cwnd的增长速率慢,而是指在TCP开始发送报文段时先设置cwnd=1,使得发送方在开始时只发送一个报文段(目的是试探一下网络的拥塞情况),然后再指数增大cwnd。
为了防止拥塞窗口cwnd增长过大引起网络拥塞,还需要设置一个慢开始门限ssthresh状态变量。慢开始门限ssthresh的用法如下:
- 当 cwnd < ssthresh 时,使用上述的慢开始算法。
- 当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。
- 当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞控制避免算法。
拥塞避免算法
让拥塞窗口cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口cwnd按线性规律缓慢增长,比慢开始算法的拥塞窗口增长速率缓慢得多。
无论在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认),就要把慢开始门限ssthresh设置为出现拥塞时的发送方窗口值的一半(但不能小于2)。然后把拥塞窗口cwnd重新设置为1,执行慢开始算法。这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够时间把队列中积压的分组处理完毕。
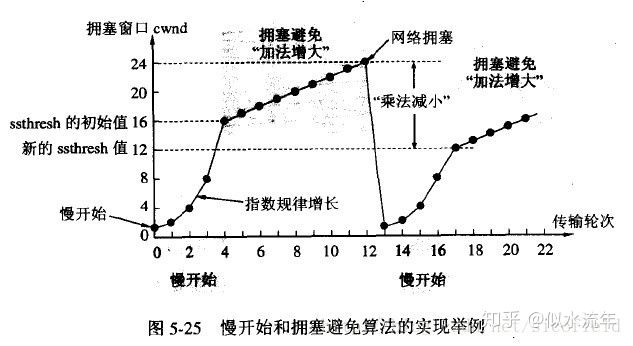
当TCP连接进行初始化时,把拥塞窗口cwnd置为1。前面已说过,为了便于理解,图中的窗口单位不使用字节而使用报文段的个数。慢开始门限的初始值设置为16个报文段,即 cwnd = 16 。
在执行慢开始算法时,拥塞窗口 cwnd 的初始值为1。以后发送方每收到一个对新报文段的确认ACK,就把拥塞窗口值加1,然后开始下一轮的传输(图中横坐标为传输轮次)。因此拥塞窗口cwnd随着传输轮次按指数规律增长。当拥塞窗口cwnd增长到慢开始门限值ssthresh时(即当cwnd=16时),就改为执行拥塞控制算法,拥塞窗口按线性规律增长。
假定拥塞窗口的数值增长到24时,网络出现超时(这很可能就是网络发生拥塞了)。更新后的ssthresh值变为12(即变为出现超时时的拥塞窗口数值24的一半),拥塞窗口再重新设置为1,并执行慢开始算法。当cwnd=ssthresh=12时改为执行拥塞避免算法,拥塞窗口按线性规律增长,每经过一个往返时间增加一个MSS的大小。
强调:“拥塞避免”并非指完全能够避免了拥塞。利用以上的措施要完全避免网络拥塞还是不可能的。“拥塞避免”是说在拥塞避免阶段将拥塞窗口控制为按线性规律增长,使网络比较不容易出现拥塞。
关于 乘法减小(Multiplicative Decrease)和加法增大(Additive Increase):
“乘法减小”指的是无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞,就把慢开始门限ssthresh设置为出现拥塞时的发送窗口大小的一半,并执行慢开始算法,所以当网络频繁出现拥塞时,ssthresh下降的很快,以大大减少注入到网络中的分组数。“加法增大”是指执行拥塞避免算法后,使拥塞窗口缓慢增大,以防止过早出现拥塞。常合起来成为AIMD算法。
快恢复算法
快重传配合使用的还有快恢复算法,有以下两个要点:
- 当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半(为了预防网络发生拥塞)。
- 但是接下去并不执行慢开始算法,考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh减半后的值,然后执行拥塞避免算法,使cwnd缓慢增大。如下图:TCP Reno版本是目前使用最广泛的版本。
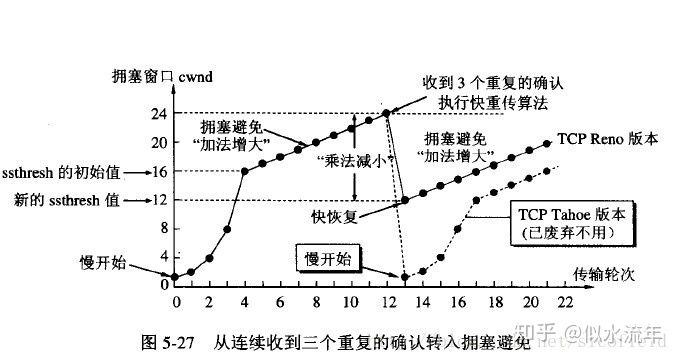
注意:在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时才使用