在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及JVM底层相关的影响因素。前段时间学习了一个牛X的高性能异步处理框架 Disruptor,它被誉为“最快的消息框架”,其LMAX架构能够在一个线程里每秒处理6百万订单!在讲到Disruptor为什么这么快时,接触到了一个概念——伪共享( false sharing ),其中提到:缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。由于从代码中很难看出是否会出现伪共享,有人将其描述成无声的性能杀手。
CPU缓存简单介绍
如果你对cpu cache不怎么理解可以看这篇文章cpu cache结构和缓存一致性(MESI协议)
为了高效地存取缓存, 不是简单随意地将单条数据写入缓存的. 缓存是由缓存行组成的, 典型的一行是64字节. 读者可以通过下面的shell命令,查看cherency_line_size就知道知道机器的缓存行是多大.
1 | cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size |
CPU存取缓存都是按行为最小单位操作的. 在这儿我将不提及缓存的associativity问题, 将问题简化一些. 一个Java long型占8字节, 所以从一条缓存行上你可以获取到8个long型变量. 所以如果你访问一个long型数组, 当有一个long被加载到cache中, 你将无消耗地加载了另外7个. 所以你可以非常快地遍历数组.
下面是利用缓存行来进行的对比实验代码
1 | public class L1CacheMiss { |
编译运行得到的结果如下
1 | starting.... |
然后我们将22-26行的注释取消, 将28-32行注释, 编译后再次运行,结果是不是比我们预想得还糟?
1 | starting.... |
通过对比可以看出,第二个花的时间是第一个的10倍还多。从上节我们可以知道在加载longs[i][j]时, longs[i][j+1]很可能也会被加载至cache中, 所以立即访问longs[i][j+1]将会命中L1 Cache, 而如果你访问longs[i+1][j]情况就不一样了, 这时候很可能会产生 cache miss导致效率低下.
以上我只是示例了在L1 Cache满了之后才会发生的cache miss. 其实cache miss的原因有下面三种:
- 第一次访问数据, 在cache中根本不存在这条数据, 所以cache miss, 可以通过prefetch解决.
- cache冲突, 需要通过补齐来解决.
- 就是我示例的这种, cache满, 一般情况下我们需要减少操作的数据大小, 尽量按数据的物理顺序访问数据
在文章开头提到过,缓存系统中是以缓存行(cache line)为单位存储的。缓存行通常是64字节(译注:本文基于 64 字节,其他长度的如 32 字节等不适本文讨论的重点),并且它有效地引用主内存中的一块地址。一个Java的long类型是8字节,因此在一个缓存行中可以存8个long 类型的变量。所以,如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个,以致你能非常快地遍历这个数组。事实上,你可以非常快速的遍历在连续的内存块中分配的任意数据结构。而如果你在数据结构中的项在内存中不是彼此相邻的(如链表),你将得不到免费缓存加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中。
如果存在这样的场景,有多个线程操作不同的成员变量,但是相同的缓存行,这个时候会发生什么?没错,伪共享(False Sharing)问题就发生了!有张Disruptor项目的经典示例图,如下: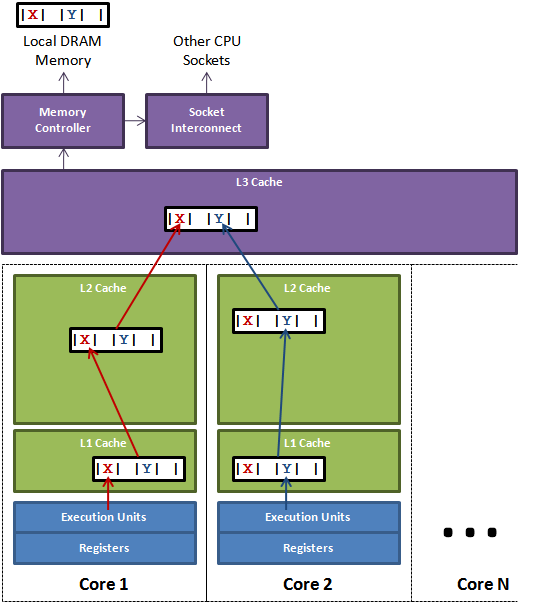
上图中,一个运行在处理器 core1上的线程想要更新变量 X 的值,同时另外一个运行在处理器 core2 上的线程想要更新变量Y的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送 RFO 消息,占得此缓存行的拥有权。当core1取得了拥有权开始更新X,则 core2 对应的缓存行需要设为 I 状态。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。从前一篇我们知道,读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上X和Y都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
遭遇伪共享
好的,那么接下来我们就用 code 来进行实验和佐证。
1 | public class FalseShareTest implements Runnable { |
上述代码的逻辑很简单,就是四个线程修改一数组不同元素的内容。元素的类型是 VolatileLong,只有一个长整型成员 value 和 6 个没用到的长整型成员。value 设为 volatile 是为了让 value 的修改对所有线程都可见。程序分两种情况执行,第一种情况为不屏蔽倒数第三行(见”屏蔽此行”字样),第二种情况为屏蔽倒数第三行。为了”保证”数据的相对可靠性,程序取 10 次执行的平均时间。执行情况如下(执行环境:32位 windows,四核,8GB 内存):
不屏蔽如下图
屏蔽如下图
两个逻辑一模一样的程序,前者的耗时大概是后者的 2.5 倍,这太不可思议了!那么这个时候,我们再用伪共享(False Sharing)的理论来分析一下。前者longs数组的4个元素,由于 VolatileLong只有1个长整型成员,所以整个数组都将被加载至同一缓存行,但有4个线程同时操作这条缓存行,于是伪共享就悄悄地发生了。
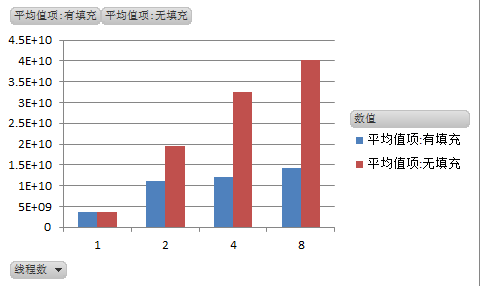
基于此,我们有理由相信,在一定线程数量范围内(注意思考:为什么强调是一定线程数量范围内),随着线程数量的增加,伪共享发生的频率也越大,直观体现就是执行时间越长。为了证实这个观点,本人在同样的机器上分别用单线程、2、4、8个线程,对有填充和无填充两种情况进行测试。执行场景是取 10 次执行的平均时间,结果如下所示:
伪共享解决方案
处理伪共享的两种方式:
- 增大数组元素的间隔使得不同线程存取的元素位于不同的cache line上。典型的空间换时间。(Linux cache机制与之相关)
- 在每个线程中创建全局数组各个元素的本地拷贝,然后结束后再写回全局数组。
在Java类中,最优化的设计是考虑清楚哪些变量是不变的,哪些是经常变化的,哪些变化是完全相互独立的,哪些属性一起变化。举个例子:
1 | public class Data{ |
假如业务场景中,上述的类满足以下几个特点:
- 当value变量改变时,modifyTime肯定会改变
- createTime变量和key变量在创建后,就不会再变化。
- flag也经常会变化,不过与modifyTime和value变量毫无关联。
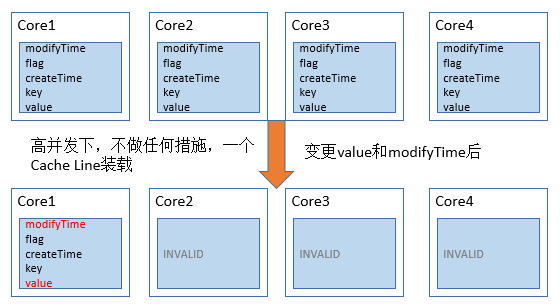
当上面的对象需要由多个线程同时的访问时,从Cache角度来说,就会有一些有趣的问题。当我们没有加任何措施时,Data对象所有的变量极有可能被加载在L1缓存的一行Cache Line中。在高并发访问下,会出现这种问题:
如上图所示,每次value变更时,根据MESI协议,对象其他CPU上相关的Cache Line全部被设置为失效。其他的处理器想要访问未变化的数据(key 和 createTime)时,必须从内存中重新拉取数据,增大了数据访问的开销。
Padding 方式
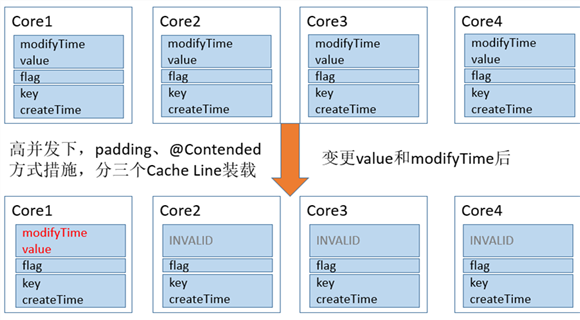
正确的方式应该将该对象属性分组,将一起变化的放在一组,与其他属性无关的属性放到一组,将不变的属性放到一组。这样当每次对象变化时,不会带动所有的属性重新加载缓存,提升了读取效率。在JDK1.8以前,我们一般是在属性间增加长整型变量来分隔每一组属性。被操作的每一组属性占的字节数加上前后填充属性所占的字节数,不小于一个cache line的字节数就可以达到要求:
1 | public class DataPadding{ |
通过填充变量,使不相关的变量分开
Contended注解方式
在JDK1.8中,新增了一种注解@sun.misc.Contended,来使各个变量在Cache line中分隔开。注意,jvm需要添加参数-XX:-RestrictContended才能开启此功能
用时,可以在类前或属性前加上此注释:
1 | // 类前加上代表整个类的每个变量都会在单独的cache line中 |
采取上述措施图示:
JDK1.8 ConcurrentHashMap的处理
java.util.concurrent.ConcurrentHashMap在这个如雷贯耳的Map中,有一个很基本的操作问题,在并发条件下进行++操作。因为++这个操作并不是原子的,而且在连续的Atomic中,很容易产生伪共享(false sharing)。所以在其内部有专门的数据结构来保存long型的数据:
1 |
|
我们看到该类中,是通过@sun.misc.Contended达到防止false sharing的目的
JDK1.8 Thread 的处理
java.lang.Thread在java中,生成随机数是和线程有着关联。而且在很多情况下,多线程下产生随机数的操作是很常见的,JDK为了确保产生随机数的操作不会产生false sharing ,把产生随机数的三个相关值设为独占cache line。
1 | (openjdk\jdk\src\share\classes\java\lang\Thread.java line:2023) |
对于伪共享,我们在实际开发中该怎么做?
通过上面大篇幅的介绍,我们已经知道伪共享的对程序的影响。那么,在实际的生产开发过程中,我们一定要通过缓存行填充去解决掉潜在的伪共享问题吗?其实并不一定。
首先就是多次强调的,伪共享是很隐蔽的,我们暂时无法从系统层面上通过工具来探测伪共享事件。其次,不同类型的计算机具有不同的微架构(如 32 位系统和 64 位系统的 java 对象所占自己数就不一样),如果设计到跨平台的设计,那就更难以把握了,一个确切的填充方案只适用于一个特定的操作系统。还有,缓存的资源是有限的,如果填充会浪费珍贵的 cache 资源,并不适合大范围应用。最后,目前主流的 Intel 微架构 CPU 的 L1 缓存,已能够达到 80% 以上的命中率。
综上所述,并不是每个系统都适合花大量精力去解决潜在的伪共享问题。