什么是http管道化
pipeline机制是在一条connection上多个http request不需要等待response就可以连续发送的技术。之前的request请求需要等待response返回后才能发起下一个request,而pipeline则废除了这项限制,新的request可以不必等待之前request的response返回就可以立即发送:
采用管道和不采用管道的请求如下图
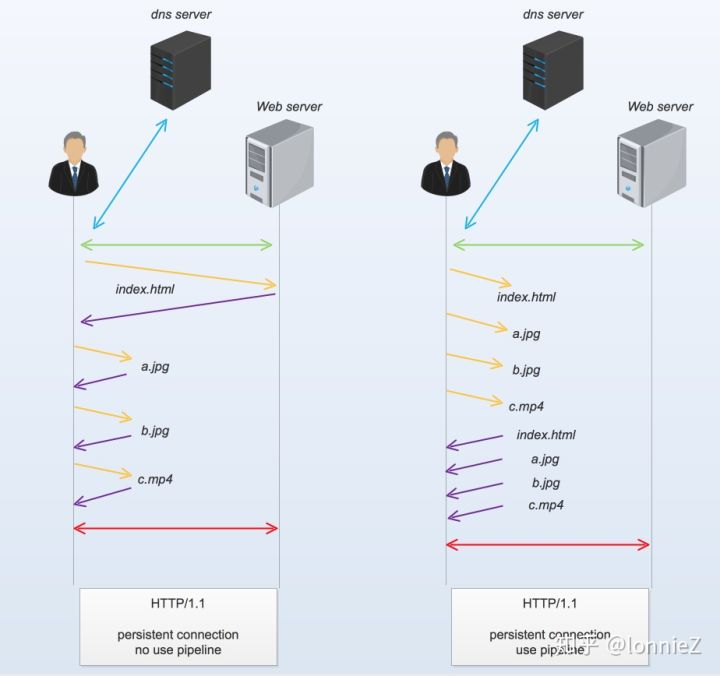
从上图中可以看出,在使用pipeline机制后,客户端无需等待上一个资源返回后就可以在同一条连接上申请下一个资源。由此可见pipeline技术可以提高每条connection的使用效率,在理想情况下,所有资源的获取仅仅需要一个RTT时长(Round Trip Time),而非pipeline的情况下,所有资源获取需要N个RTT时长(N表示资源个数)。
在理想情况下,所有资源的获取仅仅需要一个RTT时长,这看上去是非常大的优化和诱惑,但为何主流浏览器上默认下该功能都是关闭状态呢?答案只有一个:队头阻塞。我们上面仅看到了client端可以不必等待上一个response返回即可发送下一个request,但在server端必须根据收到的request的顺序来返回response,这个是因为HTTP是一个无状态的协议,每条request无法知道哪条response是返回给他的。
管道化的表现可以大大提高页面加载的速度,尤其是在高延迟连接中。 管道化同样也可以减少tcp/ip的数据包。通常MSS的大小是在536-1460字节,所以将许多个http请求放在一个tcp/ip包 里也是有可能的。减少加载一个网页所需数据包的数量可以在整体上对网络有益处,因为数据包越少,路由器和网络带来的负担就越少。 HTTP/1.1需要服务器也支持管道化。
什么时候我们应该管道化请求
只有幂等的请求才可以被管道化,比如GET和HEAD。POST和PUT不应该被管道化。所谓幂等就是 多次执行对资源的影响,和一次执行对资源的影响相同。幂等保证在pipeline中的所有请求可以不必关心发送次序和到达服务器后执行的次序,即使多次请求,返回的结果一直是一样的。反之,若其中包含了不幂等的请求,两个请求,第一个是更新用户张三信息,第二请求是获取更新后的张三最新信息。 他们是按照次序顺序在服务器端执行的:1先执行,2紧接着执行。 但是后一个请求不会等前一个请求完成才执行, 即可能 获取张三最新信息的2号请求先执行完成,这样返回的信息就不是期望的了。
我们同样也不应该在建立新连接的时候发出管道化的请求 ,因为不能确源服务或代理是否支持HTTP/1.1。因此,管道化只能利用已存在的keep-alive连接。