本文主要介绍了HTTP协议的演进过程,从HTTP/0.9到目前HTTP/2中各个版本的特点以及成因。通过对比各个版本的特点以及相关数据的支持来讲解整个HTTP协议的演进过程。此外,文中还会涉及一些相关协议概念,包括TCP/IP、DNS、HTTPS、QUIC、SPDY等,正是这些协议与HTTP一起为我们展现了一个丰富多彩的互联网的世界。
HTTP的演进
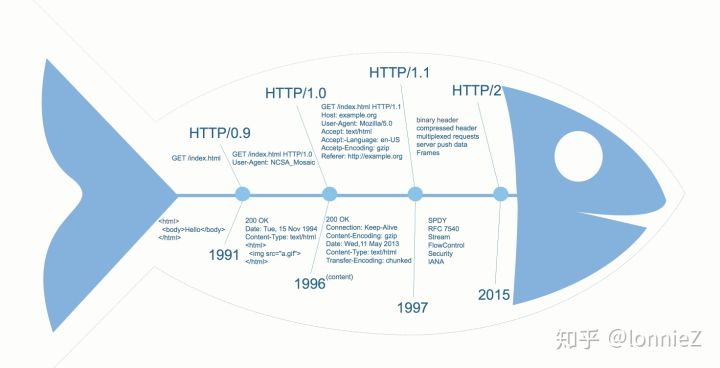
HTTP(HyperText Transfer Protocol)是万维网(World Wide Web)的基础协议,它制定了浏览器与服务器之间的通讯规则,它由Berners-Lee和他的团队在1989-1991年期间开发完成,至今共经历了3个版本的演化。
HTTP/0.9
HTTP问世之初并没有作为标准建立,被正式制定为标准是在1996年公布的HTTP/1.0协议。因此,在这之前的协议被称为HTTP/0.9
HTTP/0.9协议功能极为简单,request只有一行且只有一个GET命令,命令后面跟着的是资源路径。
1 | GET /index.html |
response同样简单,仅包含文件内容本身。
1 | <html> |
HTTP/0.9没有header的概念,也没有content-type的概念,仅能传递html文件。同样由于没有status code,当发生错误的时候是通过传递回一个包含错误描述的html文件来处理的。
此外HTTP/0.9具有无状态性,每个请求之间是独立的,当这个请求处理完成后会释放当前连接,因此可以看到HTTP协议无状态性其实是天生的,这也就有了后面的Cookie和Session技术。
HTTP/1.0
随着互联网技术的飞速发展,HTTP协议被使用的越来越广泛,协议本身的局限性已经不能满足互联网功能的多样性。因此,HTTP/1.0于1996年问世了,其内容和功能都大大增加了。对比与HTTP/0.9,新的版本包含了以下功能:
- 在每个request的GET一行后面添加版本号
- 在response中添加状态行并作为第一行返回给用户
- 在request和response中添加header的概念
- 在header中添加content-type以此可以传输html之外类型的文件
- 在header中添加content-encoding来支持不同编码格式文件的传输
- 引入了POST和HEAD命令,丰富了浏览器与服务器的交互方式
- 支持长连接(默认还是短连接)
也就是自从HTTP/1.0开始,HTTP的主要格式就定义下来,如下所示:
请求报文包含四部分:
- 请求行:包含请求方法、URI、HTTP版本信息
- 请求头部字段
- 空行
- 请求内容实体
响应报文包含四部分:
- 状态行:包含HTTP版本、状态码、状态码对应的短语
- 响应头部字段
- 空行
- 响应内容实体
一个典型的的request/response交互如下:
request内容,这里没有body,但是要注意的是,空行不能省略
1 | GET /index.html |
response内容:这里的状态行没有版本,是因为,在Http1的时候默认就是http1,所以没有加上
1 | 200 OK |
当浏览器解析html文件后,会发起第二个请求来获取图片:
请求图片的报文
1 | GET /image.gif |
响应的报文
1 | 200 OK |
此外,在HTTP/1.0中规定header信息必须是ASCII码,后面的数据可以是任何格式。因此,服务器在应答的时候需要告诉用户数据的格式,即Content-Type的作用。一些常见Content-Type:

Content-Type的每个值包括一级类型和二级类型,之间用斜杠分开;此外还可以自定义Content-Type;还可以在Content-Type中添加参数,如下面的示例,Content-Type表示发送的是网页而编码格式是utf-8.
1 | Content-Type: text/html; charset=utf-8 |
由于支持任意数据格式的发送,因此可以先把数据进行压缩再发送。HTTP/1.0进入了Content-Encoding来表示数据的压缩方式。主要由以下三种
- Content-Encoding: gzip
- Content-Encoding: compress
- Content-Encoding: deflate
关于内容文本压缩,可以参考这篇文章:Http协议中的Content-Encoding
而客户端也可以在header中添加如下信息来表明自己可以接受哪些压缩方式:
1 | Accept-Encoding: gzip, deflate |
为了解决每次请求完一个资源后连接会断开,若再请求同一个服务器上的资源需要重新建立连接的问题,HTTP/1.1引入了长连接的概念。众所周知,HTTP的建连成本是较高的,由于HTTP基于TCP协议之上,一个建立连接的过程需要DNS过程以及TCP的三次握手。随着网页资源的日益增多,每请求完一个资源需要重新建立的消耗越来越大,因此用一条长连接来获取多个资源就可以大大节省网页的访问时间,提升连接的效率。HTTP/1.1在request header中引入如下信息来告知服务器完成一次request请求后不要关闭连接:
1 | Connection: keep-alive |
同样,服务器端也会答复一个相同的信息表示连接仍然有效。这样,后面的请求就可以复用该条连接了,只可惜该条信息此时没有加入到标准中,而是一种自定义行为。HTTP/1.0的RFC1945这里有说明。不过在后来,只要是HTTP1.1,默认就是长连接,除非你加上Connection:close字段。