HTTP/1.1
仅仅在HTTP/1.0公布后的几个月,HTTP/1.1发布了,是目前主流HTTP协议的版本,也是目前为止使用最为广泛、延用时间最为久远的HTTP版本,以至于随后的近10年时间里都没有新的HTTP协议版本发布。对比之前的版本,其主要更新如下:
- 默认长连接机制
- Pipeline机制
- header中引入host
- Chunked编码传输
- 更全面的Cache机制
- 引入OPTIONS, PUT, DELETE, TRACE和CONNECT方法
keep-alive
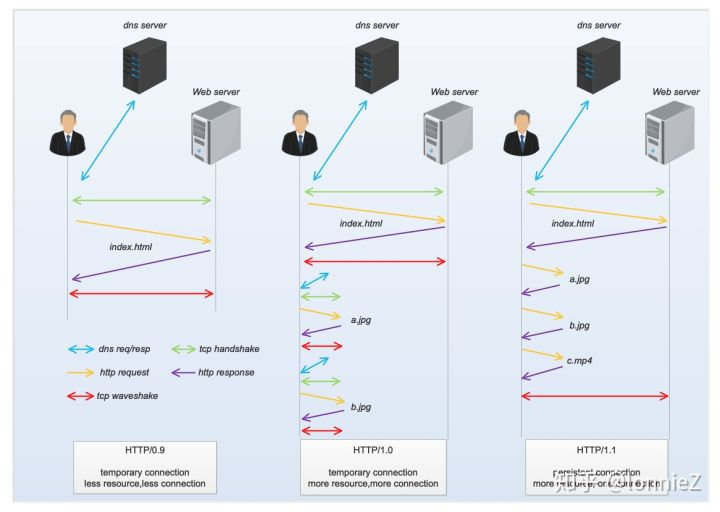
keep-alive在HTTP/1.0中已经诞生,但由于当时没有写入标准,因此这次特意提出来强调。为何keep-alive会被反复提到。可以通过下图看出keep-alive的重要性。在HTTP/0.9的时代,由于网页内容相对简单,需要向服务器申请的资源以及对应的次数相对较少,每发起一次http请求就会建立一次连接,每次建连都会涉及tcp的三次握手过程,同时建连前还需要向dns服务器查询相关的IP地址。
随着互联网的迅猛发展,网页资源也越来越多,HTTP/1.0的出现正是解决了浏览器与服务器间传递非html类型文件的需求,但随之而来的是请求次数的增多。由于每个资源的下载都需要重新建立连接,每次建连都包含tcp的三次握手,完成数据传递后又通过tcp的四次挥手关闭连接,周而复始,访问一个较为复杂的网页会消耗大量的时间。虽然在HTTP/1.0中引入了长连接的机制,但由于未加入标准,因此此时仍然是每个资源会重新建立一次连接。
好在HTTP/1.1的及时出现将长连接加入了标准并作为默认实现,服务器端也按照协议保持客户端的长连接状态。一个Web Server上的多个资源都可以通过这一条连接多个request的方式一一得到。这样可以极大的节省在建连和关闭连接过程中消耗的时间,越复杂的网站节省的时间越多。
基于HTTP的工作原理,后面又有了针对DNS和Connection的优化,不过这都是后话了。
Http0.9 到Http1.1的请求示意图如下:
为了进一步说明keep-alive的重要性,在此进行了一次测试,分别以Keep-Alive的方式和非Keep-Alive的方式对http://api.yunos.com访问5次、10次、15次、20次。以下是测试数据的对比:
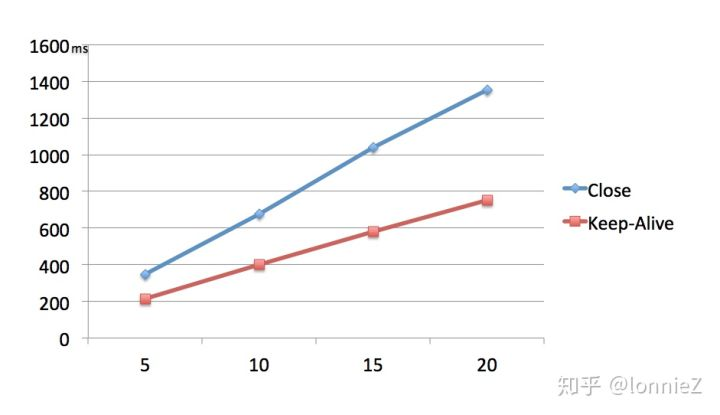
从上面的数据可以看出,随着访问次数增长Close与Keep-Alive的时间差距越来越大,除了平均耗时上的差异,还有一组方差数据的对比: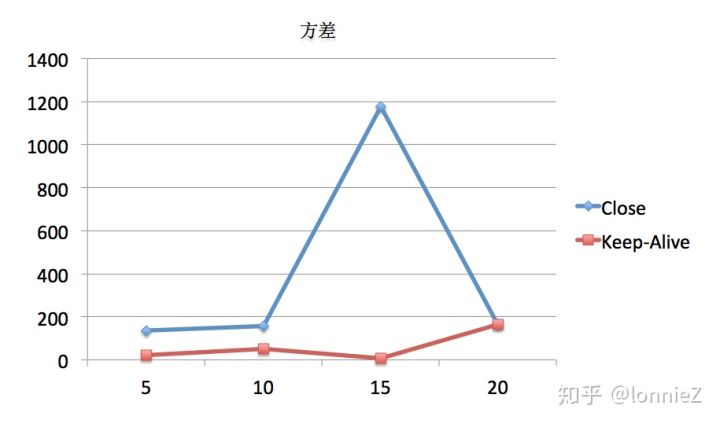
从方差数据来看,Close模式的波动要大于Keep-Alive模式。我们再从另一个角度看这个问题,从下面的数据可以看出:一个网络请求过程中DNS和Connection建连的过程会耗费很大的时间: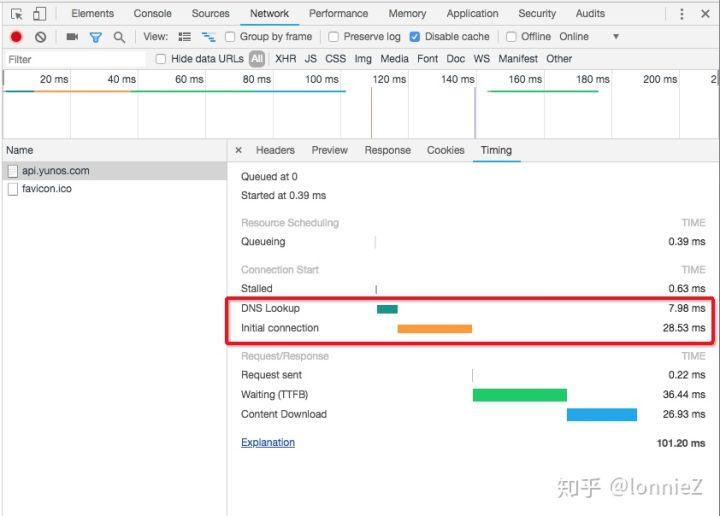
从上面的这些数据可以看出长连接对于网络访问速度的重要性,这也是为何我们在多个场合提及Keep-Alive机制。包括后续的许多优化都是针对DNS、Connection建连这两个方面进行的。
TCP中的keep-alive
上面讲述了很多关于HTTP/1.1中Keep-Alive的特性,这里需要强调的一点是此处的Keep-Alive不同于TCP层的Keep-Alive。Http层的Keep-Alive主要是保持Client端与Server端的连接不会因为一次request请求的结束而被关闭,以此来实现连接复用的目的。而TCP层的Keep-Alive则更像一种保鲜机制,即当连接建立后,相关socket可以定期向对端发送心跳包来检查连接是否还有效,用户可以设置相关的参数,包括多久开始发送、每次发送的间隔、发送次数等。如果一直没有收到对端的响应,则认为连接已经断开并释放相关资源。正常的TCP关闭流程会通知对方连接已经关闭,但是如果是一些意外情况,例如拔掉网线、有一端设备宕机或重启,此时正在执行recv或者send操作的一方就会因为没有任何连接中断的通知而一直等待下去。为了解决这个问题,引入了TCP的Keep-Alive机制。
一般情况下TCP的Keep-Alive机制是关闭的且默认参数不一定满足每个用户的需求,需要用户自行调整:
1 | // 打开Keep-Alive机制。默认是关闭的。 |
即当TCP开启保鲜机制后,当连接空闲7200秒后(默认值),会以每75秒的间隔连续发送9次心跳检测,也就是需要大概额外11分钟的时间来判断当前连接是否还可用。在上面的示例中则额外需要5*2=10秒的时间就可以判断当前连接是否可用。也可以通过如下方法来修改相关参数:
1 | // 设置空闲时长 |
以下是下载一个文件过程中拔掉网线的抓包记录。我代码中设置的keepalive_time为45秒,interval为5秒,count为9次。从抓包中可以看到从14:53:33开始断网,45秒以后,也就是14:54:18开始第一次keep-alive检查,间隔5秒后,也就是14:54:23秒开始第二次keep-alive检查,以此类推,一共经历了9次keep-alive。即断网后经历了45+5*9=90s也就是14:53:33后的90秒14:54:03后宣告网络已断开,此链接不再有效。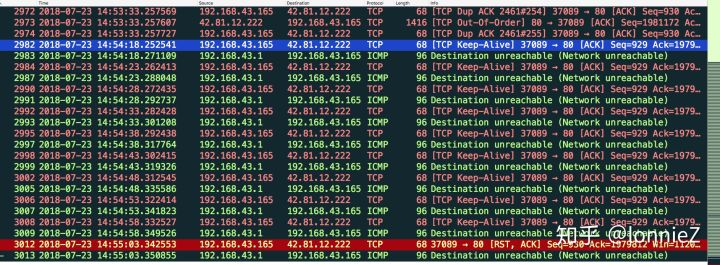
具体tcp的保活机制可以参考这篇文章tcp保活机制,可以参考这篇文章了解https://xie.infoq.cn/article/398b82c2b4300f928108ac605
pipeline
pipeline机制是在一条connection上发送多个http请求而不需要等待对应的响应返回的技术。之前的request请求需要等待response返回后才能发起下一个request,而pipeline则废除了这项限制,新的request可以不必等待之前request的response返回就可以立即发送: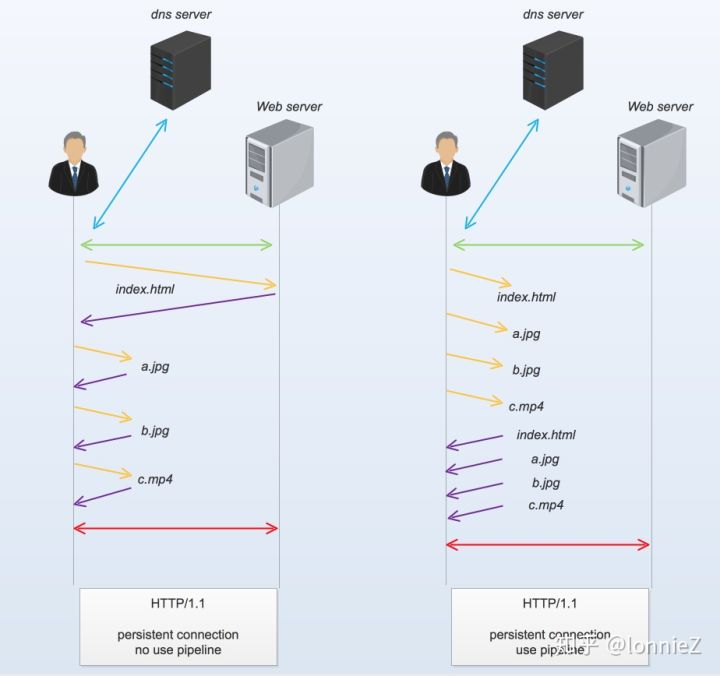
从上图中可以看出,在使用pipeline机制后,客户端无需等待上一个资源返回后就可以在同一条连接上申请下一个资源。由此可见pipeline技术可以提高每条connection的使用效率,在理想情况下,所有资源的获取仅仅需要一个RTT时长(Round Trip Time),而非pipeline的情况下,所有资源获取需要N个RTT时长(N表示资源个数)。
在理想情况下,所有资源的获取仅仅需要一个RTT时长,这看上去是非常大的优化和诱惑,但为何主流浏览器上默认下该功能都是关闭状态呢?答案只有一个:队头阻塞。我们上面仅看到了client端可以不必等待上一个response返回即可发送下一个request,但在server端必须根据收到的request的顺序来返回response,这个是因为HTTP是一个无状态的协议,每条request无法知道哪条response是返回给他的。可以参见HTTP/1.1的RFC2616中这条解释:
8.1.2.2 Pipelining A client that supports persistent connections MAY “pipeline” its requests (i.e., send multiple requests without waiting for each response). A server MUST send its responses to those requests in the same order that the requests were received.
从这个解释可以看出,如果server端来处理pipeline请求的时候出现问题,那么排在后面的request都会被block。以下是一些产品使用pipeline后产生的问题:Safari使用pipeline后发生了图片互换,AFNetworking在下载文件时遇到的问题。因此,如果既想要在一个Connection连接中传递多种数据,又想要避免队头阻塞的问题,那么后面讲到的HTTP/2会解决这个问题。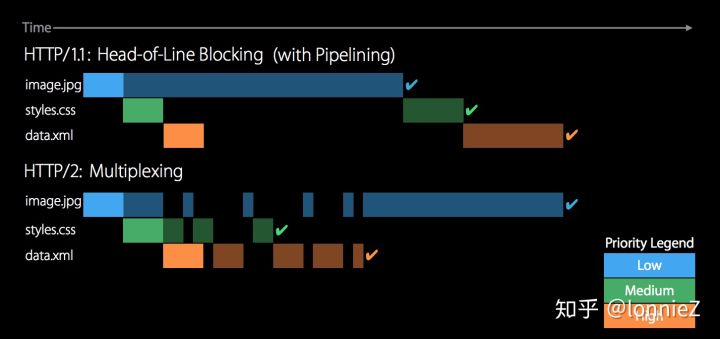
从上图可以看到虽然开启了pipeline功能,资源仍然是OneByOne的被接收到的。而HTTP/2的Multiplexing功能则可以真正意义上实现数据的同时发送与同时接收,不用再被队头阻塞限制。不过HTTP/2也只是解决了应用层协议的队头阻塞问题,而传输层的队头阻塞问题没有被解决(TCP的队头阻塞),因此就有了QUIC协议,这也是后话了。
此外关于pipeline还需要注意的是:
- 只有幂等的方法才能使用pipeline,例如GET和HEAD请求。而由于POST是非幂等的,因此不能使用pipeline;关于幂等性可以参见这里。谓幂等就是多次执行对资源的影响,和一次执行对资源的影响相同。幂等保证在pipeline中的所有请求可以不必关心发送次序和到达服务器后执行的次序,即使多次请求,返回的结果一直是一样的。反之,若其中包含了不幂等的请求,两个请求,第一个是更新用户张三信息,第二请求是获取更新后的张三最新信息。 他们是按照次序顺序在服务器端执行的:1先执行,2紧接着执行。 但是后一个请求不会等前一个请求完成才执行, 即可能 获取张三最新信息的2号请求先执行完成,这样返回的信息就不是期望的了。
- 新建立的连接由于无法得知服务端是否支持HTTP/1.1,因此也不能使用pipeline,即只能重用之前的连接时才能使用pipeline
具体的可以看这篇文章Http pipeline
并行连接
上面讲到的pipeline技术在队头阻塞的情况下并不能真正意义上提高加载资源的速度。为了解决这个问题,我们又想到了通过在浏览器端同时开启多个http connection的方式从服务端获取数据资源以提升访问速度。它的过程如下图所示。从图中我们可以看到客户端在启动的时候同时开启了三条connection同时向服务端发起请求,这三条connection互相之间是独立的,因此客户端可以通过这三条connection去下载服务端的资源。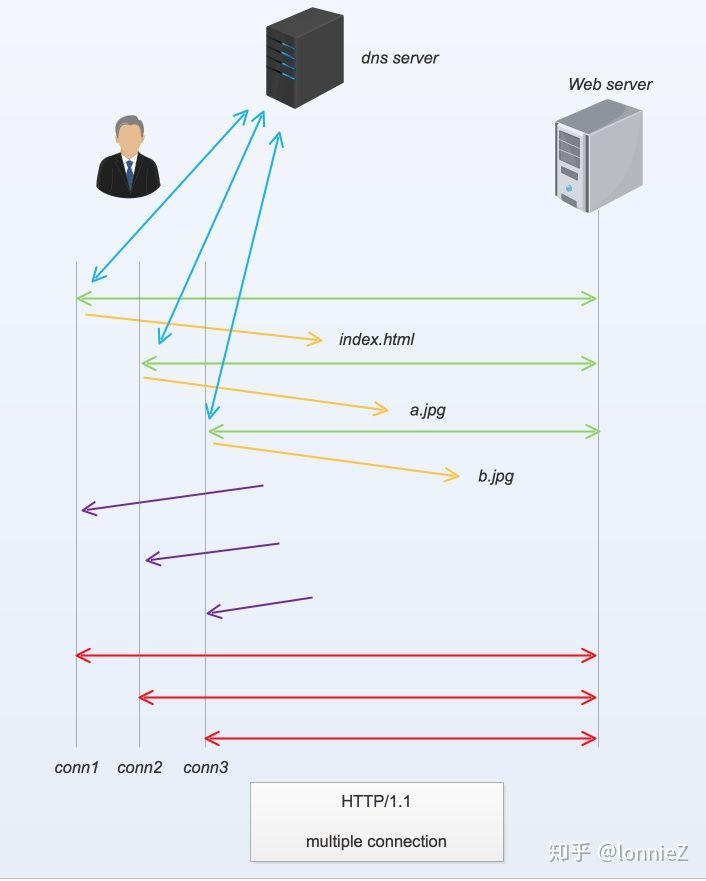
我们通过chrome浏览器在访问水木社区的时候可以看到,它在访问http:/https://cdn.jsdelivr.net/gh/fengxiu/img.newsmth.net这个域名的时候,同时开启了六个connection下载相关资源。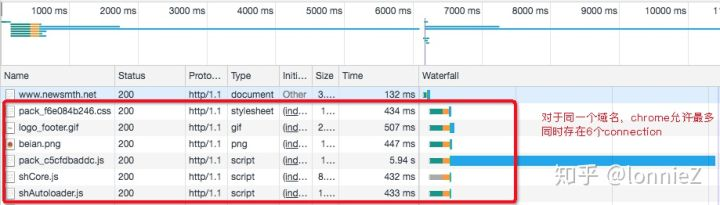
从下图可以看到每个连接都会包含DNS解析的时间和建立connection的时间。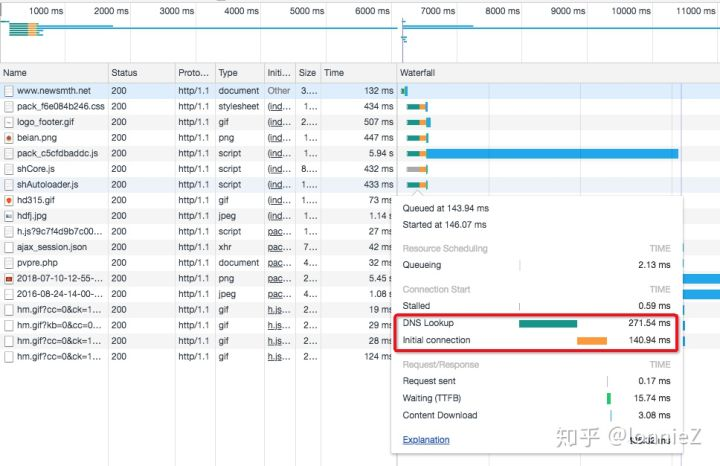
下面是抓包的数据,可以看出从浏览器侧同时发出了六个http request请求。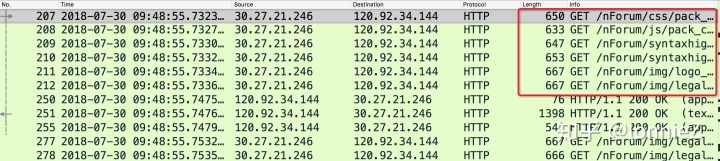
从代码的角度来看,在Chrome中设置了每一个域名最多同时可以对应六条连接。关于为何设置为六条连接可以参见这里看一下Chromium小组对此的解释。即并行连接的个数并非越多越好,这是因为每个并行连接的建立过程都会完成一次完整的DNS解析和TCP握手过程,这个过程是比较耗时和消耗资源的。此外,对于带宽有限的客户端,用户使用单连接下载一个资源的时候会占满所有带宽。如果此时开启多个连接,那么所有连接将会抢占(或平分)有限的带宽,这个过程其实并未真正对性能有所提升,反而会因为建立connection的过程而消耗很多资源。还有,过多的connection也会提升服务器端的负担。综上所述,浏览器中并行的connection不会很多。
1 | Default to allow up to 6 connections per host. Experiment and tuning may try other values (greater than 0). Too large may cause many problems, such as home routers blocking the connections!?!? See http://crbug.com/12066.WebSocket connections are long-lived, and should be treated differently than normal other connections. Use a limit of 255, so the limit for wss will be the same as the limit for ws. Also note that Firefox uses a limit of 200.See http://crbug.com/486800 |
host头域
在请求头域中新增了Host字段,其用来指定服务器的域名。有了Host字段,在同一台服务器上就可以搭建不同的网站了,这也为后来虚拟化的发展打下了基础。
1 | Host: www.alibaba-inc.com |
cache机制
Cache不仅可以提高用户的访问速率,在移动端设备上还可以为用户极大节省流量。因此,在HTTP/1.1中新增了很多与Cache相关的头域并围绕这些头域设计了更灵活、更丰富的Cache机制。
Cache机制需要解决的问题包括:
- 判断哪些资源可以被Cache及访问访问策略
- 在本地判断Cache资源是否已经过期
- 向服务端发起问询,查看已过期的Cache资源是否在服务端发生了变化
在此列出了Cache相关的头域已经他们所对应的功能:
Cache-Control
Cache-Control是Cache最重要的策略机制,通过Cache-Control与不同值的组合可以实现Cache的存储策略、访问策略以及过期策略。当指定使用public时,表明Cache资源可以被所有用户访问。它实现了上面提到的第一个功能。
1 | Cache-Control: public |
当指定使用private时,表明Cache资源仅可以对指定用户使用,对其他用户发来的请求,缓存服务器不会返回缓存。它实现了上面提到的第一个功能。
1 | Cache-Control: private |
当使用no-store的时候,表示资源不要进行缓存。它实现了上面提到的第一个功能。
1 | Cache-Control: no-store |
当no-cache在请求首部出现时表示客户端不接收缓存数据;当在响应首部出现时表示数据可以缓存,但每次使用数据前需要向服务端确认数据是否过期。它实现了上面提到的第一个和第二个功能。
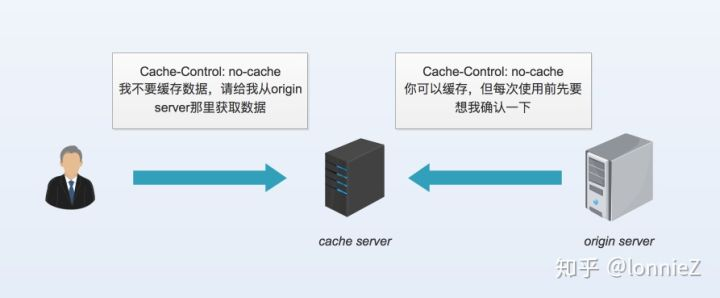
当max-age在请求首部出现时表示可以接收没有超过缓存过期后指定数值内的资源;当在响应首部出现时表示指定时间内可以不必再向服务端确认该资源的时效性。它实现了上面提到的第一个和第二个功能。
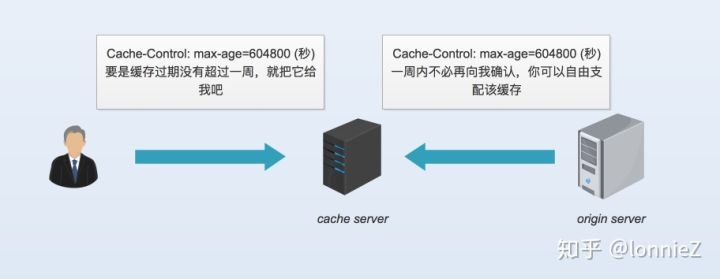
Pragma
Pragma头域是HTTP/1.0的产物。目前仅作为与HTTP/1.0的向后兼容而定义。它现在仅在请求首部中出现,表示要求所有中间服务器不返回缓存的资源,与Cache-Control: no-cache的意义相同。
1 | Pragma: no-cache |
Expires
Expires仅在响应头域中出现,表示资源的时效性。它主要解决上面的第二个问题,即当本地查询缓存的时候发现已经超过了Expires标记的时间,则会重新向server端发送请求。这里需要注意的是:当header中同时存在Cache-Control: max-age=xx和Expires的时候,以Cache-Control: max-age的时间为准。

Last-Modified
Last-Modified表明资源最终修改的时间。一般情况下,它会作为If-Modifed-Since的值传递给服务器,由服务器告之是否可以继续使用本地缓存资源,如果资源过期则返回status code 200和更新后的资源。如果可以继续使用,则返回status code 304,那么客户端将继续使用本地资源。这里它实现了上面说的第三个功能。
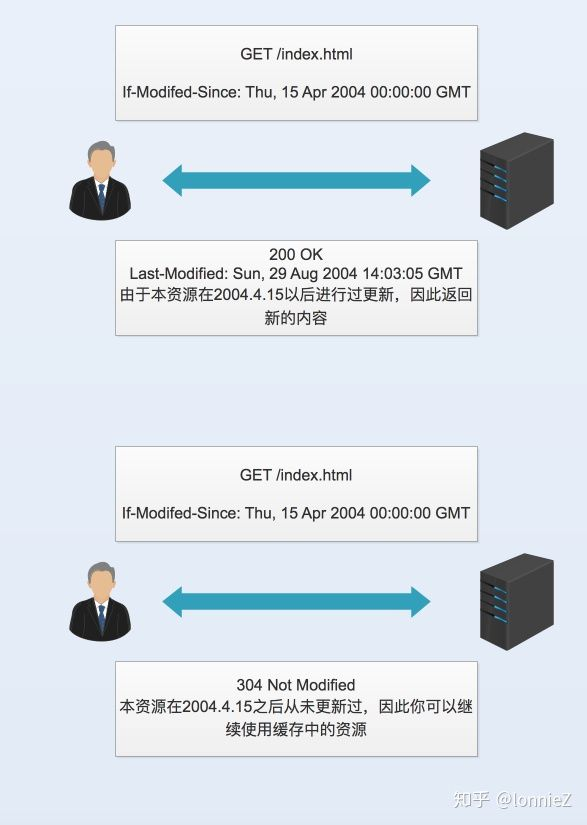
此外,Last-Modified还可以在没有Expires和Cache-Control: max-age(或no-cache)这两个头域的时候与Date头域配合制定资源的有效期。这里它实现了上面说的第二个功能:
13.2.4 Expiration Calculations
…
If none of Expires, Cache-Control: max-age, or Cache-Control: s- maxage (see section 14.9.3) appears in the response, and the response does not include other restrictions on caching, the cache MAY compute a freshness lifetime using a heuristic. The cache MUST attach Warning 113 to any response whose age is more than 24 hours if such warning has not already been added.
Also, if the response does have a Last-Modified time, the heuristic expiration value SHOULD be no more than some fraction of the interval since that time. A typical setting of this fraction might be 10%.
ETag
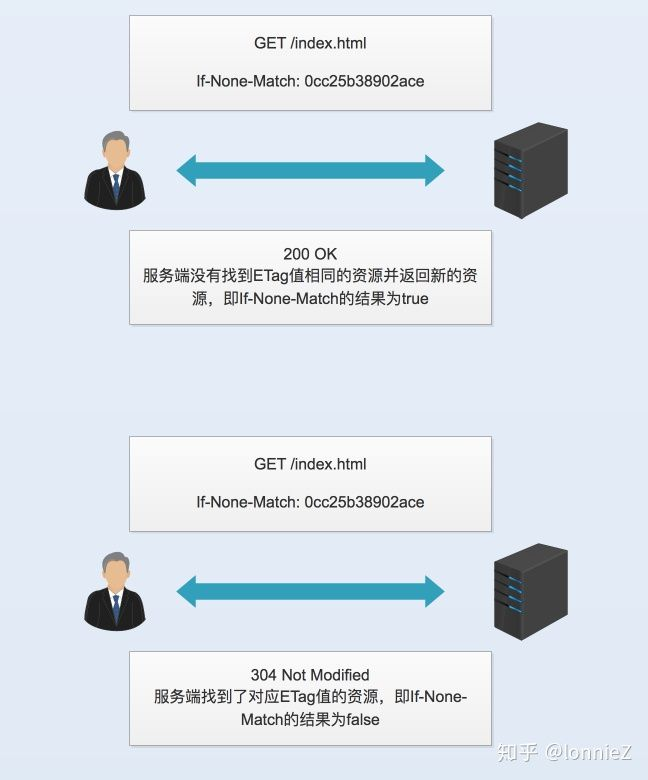
ETag字段主要用来告之客户端一个资源的标识。它是一种可以将资源以字符串形式做唯一性标识的方式。服务器端会为每个资源分配对应的ETag值,当资源更新时ETag值也会更新。一般情况下,它会作为If-None-Match的值传递给服务端,用来查询相关资源是否更新,如果已经更新则返回200,如果没有更新则返回304.
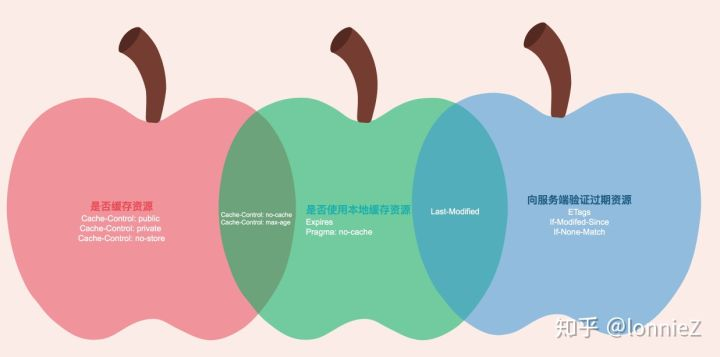
结合以上Cache功能和头域,我们可以把实现这三个功能与相关头域做以下的划分。如下图所示,其中有部分头域可以实现多个功能,因此以重叠的形式存在。
chunked机制
用户通常会通过response header中返回的Content-Length来判断服务端返回数据的大小。但随着网络技术的不断发展,越来越多的动态资源被引入进来,这时候服务端就无法在传输之前知道待传递资源的大小,也就无法通过Content-Length来告知用户资源大小。服务器可以一边动态产生资源,一边传递给用户,这种机制称为“分块传输编码”(Chunkded Transfer Encoding),它是在HTTP/1.1中引入的,允许服务端发送给客户端的数据分为多个部分,此时服务器端需要在header中添加“Transfer-Encoding: chunked”头域来替代传统的“Content-Length”。因此,当你在response header中没有找到对应的Content-Length的时候,该header中一定会包含“Transfer-Encoding: chunked”。
1 | 200 OK |
如果一个Http Response Header的中包含Transfer-Encoding: chunked头域,那么其消息体由数量未定的块组成,且以最后一个大小为0的块结束。每一个非空块都以该块包含的字节数开始,跟随一个CRLF(回车即换行),然后是数据本身,最后以CRLF结束本块。最后一个块是单行,由块大小(0)以及CRLF组成。整个消息最后以CRLF结尾。如上图所示,解析如下:
1 | 前两个块的数据中包含有显示的\r\n字符 |
以下是一个具体的示例: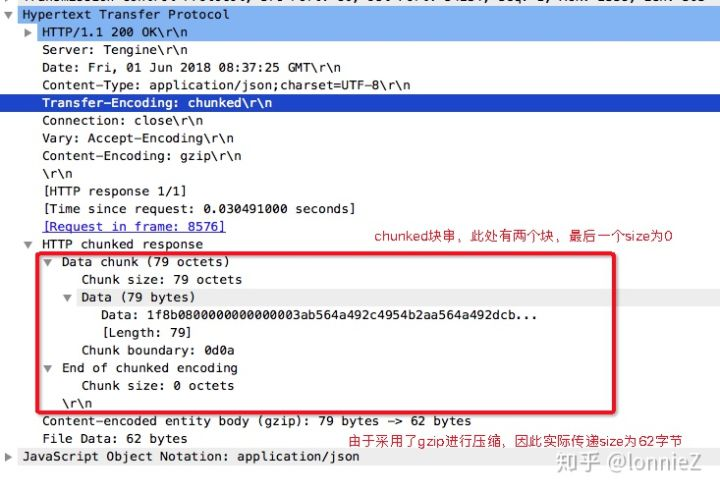
这一块具体可以参考Http值传输编码(Transfer-Encoding)