本篇文章首先会对HashTable进行简单的介绍,然后对其源码进行分析,最后总结下HashTable和HashMap之间的区别,
HashTable介绍
HashTable是一个散列表,和HashMap类似,他存储的内容是键值对(key-value)映射。类图如下

HashTable继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
HashTable的函数都是同步的,这意味着他是线程安全的。
它的key,value都不可以为null。此外HashTable的映射不是有序的。
源码分析
首先看下重要的属性
1 |
|
Hashtable的实例有两个参数影响其性能:初始容量 和 加载因子。
容量是哈希表中桶的数量,初始容量就是哈希表创建时的容量。注意,哈希表的状态为open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。
加载因子是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用rehash方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
构造方法
Hashtable有4个构造方法,如下所示:
- public Hashtable(int initialCapacity, float loadFactor):参数指定初始化容量和加载因子
- public Hashtable(int initialCapacity):参数指定初始化容量,其内部实际上是调用了上一个构造方法,其加载因子是默认的值 0.75
- public Hashtable():默认的构造方法,其内部调用了第一个构造方法,指定的初始化容量为11,加载因子是 0.75
- public Hashtable(Map<? extends K, ? extends V> t):将一个Map类型的集合全部添加到Hashtable中,内部实际调用了putAll方法
内部结构
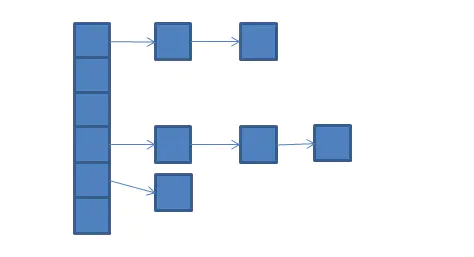
上图为Hashtable的内部结构,实际上我们通过Entry <?,?>[] table就可以看出,Hashtable内部为一个Entry<?,?>类型的数组,而Entry的结构如下所示,从而可以看出Hashtable是数组连表,既然是一个数组链表就会存在hash冲突的情况,下面就通过Hashtable中的实现细节,来探寻其中的奥秘。
1 | private static class Entry<K,V> implements Map.Entry<K,V> { |
实现细节
put方法
1 | public synchronized V put(K key, V value) { |
如上为Hashtable中添加key-value的方法,通过源码可以看出主要流程分为以下几步:
- 判空处理:对于value为空的情况,将抛出NullPointerException,在定义时发现Hashtable是不允许key,value都为null的,但这里为什么没有加以判断呢,原来每个key值将会获取其hash,即必须调用key.hashCode()方法,此时key为null是也会抛出NullPointerException,这也就是为什么Hashtable不允许key,value为NULL值。
- 定位:这一步其实很好理解,由于Hashtable是数组链表结构,首先需要定位到其在数组中的位置,使用(hash & 0x7FFFFFFF) % tab.length的方式,有可能你会奇怪 hash & 0x7FFFFFFF 这个有什么作用,我的理解是因为hash值是int类型,那么hash值有可能是负数,而负数的二进制标志是最高位,则和0x7FFFFFFF做与操作即是将负数变成正数,确保了获取到的index是正数。
- 遍历:遍历主要是查看是否已经存在需要添加的key-value,若已经存在则用新值替换老值,并返回老值,否则新增节点,这个操作主要是在addEntry方法中进行,如下是addEntry方法的源码,其流程是判断当前元素个数是否大于扩容阈值,若大于则rehash,否则新增节点并将该节点添加到对应的位置
1 | private void addEntry(int hash, K key, V value, int index) { |
rehash方法
在上文中提到在当前元素个数大于扩容阈值时,会调用rehash方法进行扩容操作并且重新分布元素的位置,而阈值threshold=capacity * loadFactor,所以当capacity一定时,可以通过负载因子loadFactor去控制阈值的大小,负载因子loadFactor越大则阈值threshold越大,反而
负载因子loadFactor越小则阈值threshold越小,可以根据实际情况调整负载因子的大小从而调节Hashtable的性能。
下面为rehash方法的源码
1 | protected void rehash() { |
从源码中可以看出rehash的过程实际上是扩容并重新分布的过程,主要包括以下几个步骤:
- 扩容:需要注意的是扩容是2*原容量 + 1
- 创建新数组:创建一个新的Entry[],其容量为扩容后的新的容量
- 分布元素:将旧数组中的元素分布到新数组中
get方法
如下为Hashtable通过key值获取对应的value值的方法,其流程比较简单,和添加中存在部分类似,根据key值定位(此时若key为null,也将会报NullPointerException),然后遍历查找对应的值,若没找到则返回null
1 | public synchronized V get(Object key) { |
对比
其实通过本文的介绍你会发现Hashtable与HashMap存在很多相似的地方,下面来介绍下HashMap与Hashtable的区别:
- 实现:HashMap继承的类是AbstractMap类,而Hashtable继承的是Dictionary类,而Dictionary是一个过时的类,因此通常情况下建议使用HashMap而不是使用Hashtable
- 内部结构:其实HashMap与Hashtable内部基本都是使用数组-链表的结构,但是HashMap引入了红黑树的实现,内部相对来说更加复杂而性能相对来说应该更好
- NULL值控制:通过前面的介绍我们知道Hashtable是不允许key-value为null值的,Hashtable对于key-value为空的情况下将抛出NullPointerException,而HashMap则是允许key-value为null的,HashMap会将key=null方法index=0的位置。
- 线程安全:通过阅读源码可以发现Hashtable的方法中基本上都是有synchronized关键字修饰的,但是HashMap是线程不安全的,故对于单线程的情况下来说HashMap的性能更优于Hashtable,单线程场景下建议使用HashMap.
总的来说,建议在单线程的情况下尽量使用HashMap。