概述
- 用法简介
- 源码分析
- 底层实现原理
1. 用法简介
LockSupport是用来创建锁和其他同步器的基本线程阻塞原语。LockSupport提供park()和unpark()方法实现阻塞线程和解除线程阻塞。每个使用LockSupport的线程都与一个许可(permit)关联,permit相当于开关,默认是0,调用一次unpark就加1变成1,调用一次park会消费permit, 也就是将1变成0,同时park立即返回。再次调用park会变成block(因为permit为0,会阻塞在这里,直到permit变为1), 这时调用unpark会把permit置为1。每个线程都有一个相关的permit, permit最多只有一个,重复调用unpark也不会积累。
park()和unpark()不会有Thread.suspend和Thread.resume所可能引发的死锁问题。这个死锁问题的产生是由于Thread.resume在Thread.suspend之前调用,使得线程忽略了解除阻塞的信号,而使得线程一直被阻塞。而LockSupport由于许可的存在,调用park的线程和另一个试图将其unpark的线程之间的竞争将保持活性。不会因为前后调用的顺序而产生死锁
如果调用线程被中断,则park方法会返回。同时park也拥有可以设置超时时间的版本。
需要特别注意的一点:park方法还可以在其他任何时间毫无理由地返回,因此通常必须在重新检查返回条件的循环里调用此方法。至于为什么后面会说到。从这个意义上说,park 是忙碌等待的一种优化,它不会浪费这么多的时间进行自旋,但是必须将它与 unpark 配对使用才更高效。
官方推介的使用方式如下
1 | while(!canprocess()){ |
调用park,可以传入一个blocker对象参数。此对象在线程受阻塞时被记录,以允许监视工具和诊断工具确定线程受阻塞的原因。(这样的工具可以使用方法 getBlocker(java.lang.Thread) 访问blocker)建议最好使用这些形式,而不是不带此参数的原始形式。在锁实现中提供的作为blocker的普通参数是Thread.currentThread。
看下线程dump的结果来理解blocker的作用。
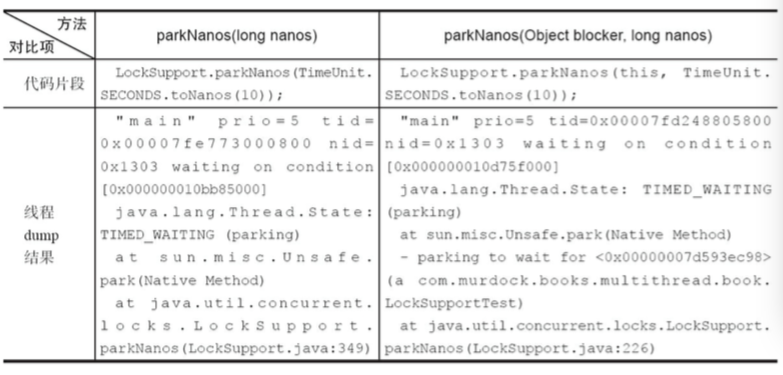
从线程dump结果可以看出:
有blocker的可以传递给开发人员更多的现场信息,可以查看到当前线程的阻塞对象,方便定位问题。所以java6新增加带blocker入参的系列park方法,替代原有的park方法。
demo1
看一个Java docs中的示例用法:一个先进先出非重入锁类的框架
1 | class FIFOMutex { |
运行结果
1 | Thread 0 Completed [0] |
从结果可以看出,运行结果可以看出,确实是先进先出类型的锁,同时也验证了没有俩个线程同时获取修改list的时机,因为如果同时修改List回抛出异常,这里没有。从侧面验证了锁的正确性
demo2
验证一下,在park之前多次调用unpark,是否会累加
1 | public class LockSupportStudy2 { |
运行结果
1 | 暂停线程 |
从实验结果可以看出,不管在park之前调用了多少次的unpark,只会唤醒一次相应的线程阻塞。
另外这个实验可以看出park和unpark的先后顺序是不重要的,因此park()和unpark()不会有 “Thread.suspend和Thread.resume所可能引发的死锁” 问题,由于许可的存在,调用 park 的线程和另一个试图将其 unpark 的线程之间的竞争将保持活性。
2. 源码分析
LockSupport中主要的两个成员变量:
1 | private static final sun.misc.Unsafe UNSAFE; |
unsafe:全名sun.misc.Unsafe可以直接操控内存,被JDK广泛用于自己的包中,如java.nio和java.util.concurrent。但是不建议在生产环境中使用这个类。因为这个API十分不安全、不轻便、而且不稳定。LockSupport的方法底层都是调用Unsafe的方法实现。
再来看parkBlockerOffset:
parkBlocker就是第一部分说到的用于记录线程被谁阻塞的,用于线程监控和分析工具来定位原因的,可以通过LockSupport的getBlocker获取到阻塞的对象。
1 | static { |
从这个静态语句块可以看的出来,先是通过反射机制获取Thread类的parkBlocker字段对象。然后通过sun.misc.Unsafe对象的objectFieldOffset方法获取到parkBlocker在内存里的偏移量,parkBlockerOffset的值就是这么来的.
JVM的实现可以自由选择如何实现Java对象的布局,也就是在内存里Java对象的各个部分放在哪里,包括对象的实例字段和一些元数据之类。 sun.misc.Unsafe里关于对象字段访问的方法把对象布局抽象出来,它提供了objectFieldOffset()方法用于获取某个字段相对 Java对象的起始地址的偏移量,也提供了getInt、getLong、getObject之类的方法可以使用前面获取的偏移量来访问某个Java 对象的某个字段。
为什么要用偏移量来获取对象?干吗不要直接写个get,set方法,多简单?
仔细想想就能明白,这个parkBlocker就是在线程处于阻塞的情况下才会被赋值。线程都已经阻塞了,如果不通过这种内存的方法,而是直接调用线程内的方法,线程是不会回应调用的。
LockSupport的方法:
1 | public static Object getBlocker(Thread t) |
可以看到,LockSupport中主要是park和unpark方法以及设置和读取parkBlocker方法。
1 | private static void setBlocker(Thread t, Object arg) { |
对给定线程t的parkBlocker赋值。
1 | public static Object getBlocker(Thread t) { |
从线程t中获取它的parkBlocker对象,即返回的是阻塞线程t的Blocker对象。
接下来主查两类方法,一类是阻塞park方法,一类是解除阻塞unpark方法
阻塞线程
- park()
1 | public static void park() { |
调用native方法阻塞当前线程。
- parkNanos(long nanos)
1 | public static void parkNanos(long nanos) { |
阻塞当前线程,最长不超过nanos纳秒,返回条件在park()的基础上增加了超时返回。
- parkUntil(long deadline)
1 | public static void parkUntil(long deadline) { |
阻塞当前线程,直到deadline时间(deadline - 毫秒数)。
JDK1.6引入这三个方法对应的拥有Blocker版本。
- park(Object blocker)
1 | public static void park(Object blocker) { |
- 记录当前线程等待的对象(阻塞对象);
- 阻塞当前线程;
- 当前线程等待对象置为null。
- parkNanos(Object blocker, long nanos)
1 | public static void parkNanos(Object blocker, long nanos) { |
阻塞当前线程,最长等待时间不超过nanos毫秒,同样,在阻塞当前线程的时候做了记录当前线程等待的对象操作。
- parkUntil(Object blocker, long deadline)
1 | public static void parkUntil(Object blocker, long deadline) { |
阻塞当前线程直到deadline时间,相同的,也做了阻塞前记录当前线程等待对象的操作。
唤醒线程
- unpark(Thread thread)
1 | public static void unpark(Thread thread) { |
唤醒处于阻塞状态的线程Thread。
3. 底层实现原理
从LockSupport源码可以看出,park和unpark的实现都是调用Unsafe.park和Unsafe.unpark,因此只要找到这俩个的底层实现原理,就可以明白park和unpark的底层实现。
HotSpot 里 park/unpark 的实现
每个java线程都有一个Parker实例,Parker类是这样定义的:
1 | class Parker : public os::PlatformParker { |
可以看到Parker类实际上用Posix的 mutex,condition来实现的。
在Parker类里的_counter字段,就是用来记录所谓的许可的。
当调用park时,先尝试直接能否直接拿到许可,即_counter>0 时,如果成功,则把_counter设置为 0, 并返回:
1 | void Parker::park(bool isAbsolute, jlong time) { |
如果不成功,则构造一个ThreadBlockInVM,然后检查_counter是不大于0,如果是,则把_counter设置为0,unlock mutex 并返回:
1 | ThreadBlockInVM tbivm(jt); |
否则,再判断等待的时间,然后再调用pthread_cond_wait函数等待,如果等待返回,则把_counter设置为0,unlock mutex 并返回
1 | if (time == 0) { |
当unpark时,则简单多了,直接设置_counter为1,再 unlock mutext 返回。如果_counter之前的值是0,则还要调用pthread_cond_signal唤醒在park中等待的线程
1 | void Parker::unpark() { |
简而言之,是用 mutex 和condition保护了一个_counter 的变量,当 park 时,这个变量置为了 0,当 unpark 时,这个变量置为 1。
值得注意的是在park函数里,调用pthread_cond_wait时,并没有用while来判断,所以posix condition里的 “Spurious wakeup” (虚假唤醒)一样会传递到上层Java的代码里,这也是官方为什么推介使用while方式的原因。
虚假唤醒简单的理解是虽然被唤醒了,但是还是不满足执行的条件,因此需要在唤醒之后判断是否满足条件,只有满足条件才执行,不然接着阻塞
关于”Spurious wakeup”,参考这篇文章:Why does pthread_cond_wait have spurious wakeups?
不过在看这篇文章之前,最好看看《Unix环境高级编程》这本书第11章节
1 | if (time == 0) { |
这也就是为什么 Java dos 里提到,当下面三种情况下 park 函数会返回:
- Some other thread invokes unpark with the current thread as the target; or
- Some other thread interrupts the current thread; or
- The call spuriously (that is, for no reason) returns.
相关的实现代码在:
http://hg.openjdk.java.net/jdk7/jdk7/hotspot/file/81d815b05abb/src/share/vm/runtime/park.hpp
http://hg.openjdk.java.net/jdk7/jdk7/hotspot/file/81d815b05abb/src/share/vm/runtime/park.cpp
http://hg.openjdk.java.net/jdk7/jdk7/hotspot/file/81d815b05abb/src/os/linux/vm/os_linux.hpp
http://hg.openjdk.java.net/jdk7/jdk7/hotspot/file/81d815b05abb/src/os/linux/vm/os_linux.cp