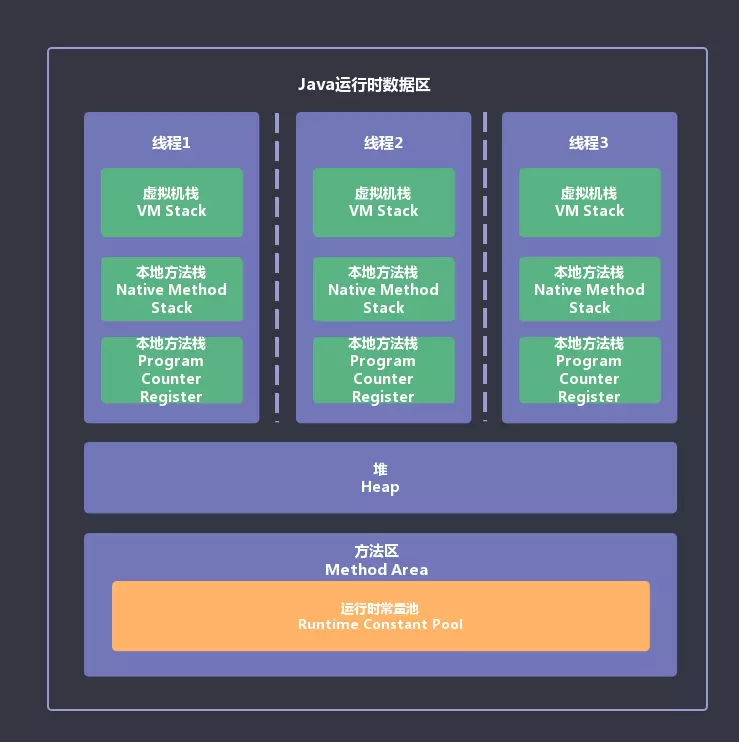
下面记录的是我面腾讯TEG事业群的经历
腾讯一面 2019年03月13日
自我介绍:我主要的是介绍我的项目,因为是很突然的接到电话,当时也没准备自我介绍,就直接将简历上面的项目介绍了一遍。但是自我的感觉介绍不是太好,因为我自己都觉得讲的不是很清楚。所以如果你要参加面试前,最好先写一个简单的自我介绍,如果是项目介绍,最好先介绍下背景,然后在介绍整个项目。这样面试官相对好理解写。不过最好不要把项目介绍的太仔细,要留下一些点让面试官自己来提问。这个度需要自己把握,。
tcp三次握手:就是简单的问了一下这个问题,面试官没有问为什么需要三次握手。可能是我在回答这个问题的时候讲了自己遇到的一个”connection by peer reset“异常,然后描述了一下自己是怎么解决这个问题的。
java 垃圾回:这个几乎只要是面java的都会问,所以需要好好整理
java中的锁:这个主要问的是Synchronize和lock的区别,以及怎么的选择。
限流:我主要说了一个根据访问的量来进行限流,后面面试官说可以通过信号量来限流。
raft:这个主要是考分布式相关的问题,然后我说只记得一点,把自己记得的讲了出来。
mapreduce:这个也是在问分布式相关的问题,但是还是忘记了,然后把自己记得的讲了出来。
后面就是面试官问我还有什么想问他的,问了一下具体部门,他们是做中间件和大数据相关的组。
一面总结
面试官主要对我的一个项目比较感兴趣,主要也在问我这个项目。不过其中有一些点没有讲的很好,比如我在项目中用到了负载均衡,但是我没有仔细的看过负载均衡实现的方法,就简单的回答了一下。所以你写在简历上的项目一点要仔细的整理。
以前自己看过很多的论文,但是都没有仔细整理,这次面试也凸显出来,所以自己看过的知识点一定要好好整理。知道不代表懂。
尽量不要紧张,因为这是我第一次面大公司所以比较紧张。不过这个也没有什么好办法,尽量多面点就不会紧张。
和面试管尽量不要保持他问你答的状态,最好是处于一种聊天的状态。这次面试前面就是因为他问我搭所以比较紧张,在面试一会之后就转入了一种在聊天的状态,紧张感也就没有了。
腾讯二面 2019年03月27日
项目介绍:和上面一样
自定义协议:如和自定义协议,也是项目中的一个问题,我当时回答的是:协议定义是非常难的一个问题,要考虑很多的方面,比如完整性和尽量减少跟数据无关的协议头的长度。然后我只是简单的将自己在项目中使用了自定义协议,主要是因为我发现在这个项目里面数据传输几乎都是一样的,所以就自定义了一个协议,但是这个自定义的协议非常的粗糙。如果不是比赛的话,我不会这样做,因为要提升性能才这样做的。但是在真正的生产环境中要考虑适配和兼容性这些问题,最好还是使用通用性协议
线程,线程是如何调度,Java线程是如何调度
你觉得你项目有什么难点
快速排序:这个问题当时没回答好,因为我吧快排和希尔排序弄混,所以就和面试官分别介绍了这俩个排序,然后总结了一下为什么快排相对来说比较好。主要胜在平均性能。
二面总结
其实问题不是太难,但是自己在回答的过程中思路不是太清晰,所以自我感觉回答的不是太好。另外一些基础的问题没有弄好。所以下来需要整理。
这个面试完了之后,也是在周五下午,进行了最后一轮的HR面试。至此我的腾讯实习面试之路走完。另外我的二面其实在前一周也可以结束,但是因为自己手机调整成了静音,没有接到电话,所以空等了一周,拖到了这周面试。所以在面试过程中手机千万不要调成静音。