配置github pages 个人域名
向你的 Github Pages 仓库添加一个CNAME(一定要*大写*)文件
其中只能包含一个顶级域名,像这样:
1 | example.com |
在使用SpringBoot的时候,我们经常看到一些@Enable*之类的开启对某些特性的支持。类如下面举的例子
通过简单的@Enable*来开启一项功能的支持,从而避免自己配置大量的代码,大大降低使用难度。那么这个神奇的功能的实现原理是什么呢?下面来研究一下。
我们知道在使用springboot的时候,都会我们只需要在application.yml或者application.properties中指定配置参数就可以使用,那这是如何实现的,本篇文章就通过一个简单例子来解释springboot是如何实现自动配置。
在http早期,每个http请求都要求打开一个tpc socket连接,并且使用一次之后就断开这个tcp连接。使用keep-alive可以改善这种状态,即在一次TCP连接中可以持续发送多份数据而不会断开连接。通过使用keep-alive机制,可以减少tcp连接建立次数,也意味着可以减少TIME_WAIT状态连接,以此提高性能和提高http服务器的吞吐率(更少的tcp连接意味着更少的系统内核调用,socket的accept()和close()调用)。
但是,keep-alive并不是免费的午餐,长时间的tcp连接容易导致系统资源无效占用。配置不当的keep-alive,有时比重复利用连接带来的损失还更大。所以,正确地设置keep-alive timeout时间非常重要。
pipeline机制是在一条connection上多个http request不需要等待response就可以连续发送的技术。之前的request请求需要等待response返回后才能发起下一个request,而pipeline则废除了这项限制,新的request可以不必等待之前request的response返回就可以立即发送:
采用管道和不采用管道的请求如下图
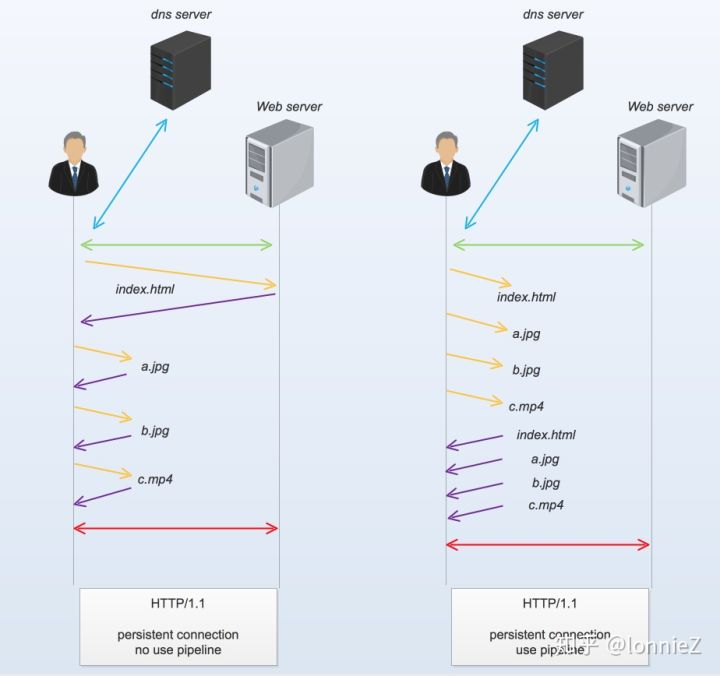
从上图中可以看出,在使用pipeline机制后,客户端无需等待上一个资源返回后就可以在同一条连接上申请下一个资源。由此可见pipeline技术可以提高每条connection的使用效率,在理想情况下,所有资源的获取仅仅需要一个RTT时长(Round Trip Time),而非pipeline的情况下,所有资源获取需要N个RTT时长(N表示资源个数)。
在理想情况下,所有资源的获取仅仅需要一个RTT时长,这看上去是非常大的优化和诱惑,但为何主流浏览器上默认下该功能都是关闭状态呢?答案只有一个:队头阻塞。我们上面仅看到了client端可以不必等待上一个response返回即可发送下一个request,但在server端必须根据收到的request的顺序来返回response,这个是因为HTTP是一个无状态的协议,每条request无法知道哪条response是返回给他的。
管道化的表现可以大大提高页面加载的速度,尤其是在高延迟连接中。 管道化同样也可以减少tcp/ip的数据包。通常MSS的大小是在536-1460字节,所以将许多个http请求放在一个tcp/ip包 里也是有可能的。减少加载一个网页所需数据包的数量可以在整体上对网络有益处,因为数据包越少,路由器和网络带来的负担就越少。 HTTP/1.1需要服务器也支持管道化。
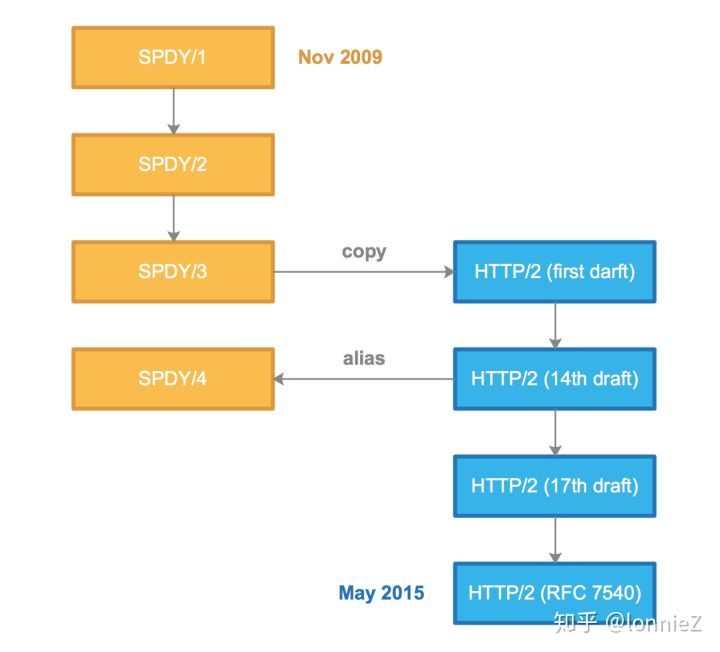
鉴于SPDY的成功,HTTP/2的开发计划也呼之欲出并且众望所归的采用了SPDY作为整个方案的蓝图进行开发。由IETF推动,Google等公司重点参与并于2015年3月公布了草案。其最终RFC可以参考这里。
先来分析一下通信协议TCP/UDP:
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
由于TCP无消息保护边界, 需要在消息接收端处理消息边界问题。也就是为什么我们以前使用UDP没有此问题。 反而使用TCP后,出现少包的现象。
在上面的章节中我们介绍了HTTP协议的一些特点,包括长连接、pipeline、并行连接等。2012年Google推出了SPDY(speedy,翻译为“快速的”)协议,旨在根本上解决HTTP协议中存在的一些问题、提升HTTP的传输效率。而随后诞生的HTTP/2也继承了SPDY的很多特性。因此,在介绍HTTP/2之前,有必要先简单了解一下SPDY的基本特征。首先,我们看一下SPDY的协议栈。由下图可见,SPDY位于HTTP和SSL之间,它属于应用层协议,当发现对端不支持SPDY的情况下,仍然可以延用HTTP/HTTPS协议,因此它可以最大程度的兼容HTTP协议。
同源策略(Same-Origin Policy)是浏览器访问网页过程中最基础的安全策略。它仍然是由大名鼎鼎的网景公司提出的(网景公司对HTTP、SSL等协议的制定做出了巨大贡献,只是在随后的浏览器大战中输给了以垄断见长的微软IE)。所谓同源是指浏览器访问目标url的域名(domain)、协议(protocol)、端口(port)这三个要素是相同的。所谓“同源策略”是指A页面里的脚本通过XHR和Fetch等方式加载B页面资源时,如果发现B页面与A页面不是“同源”的,则会禁止访问(准确的说是对跨域请求的返回结果进行屏蔽)。下图显示了一个由script发出的非同源请求,数据最终会在browser端被屏蔽。