Http的演进之路之五
声明,此系列文章转载自lonnieZ http的演进之路
SPDY
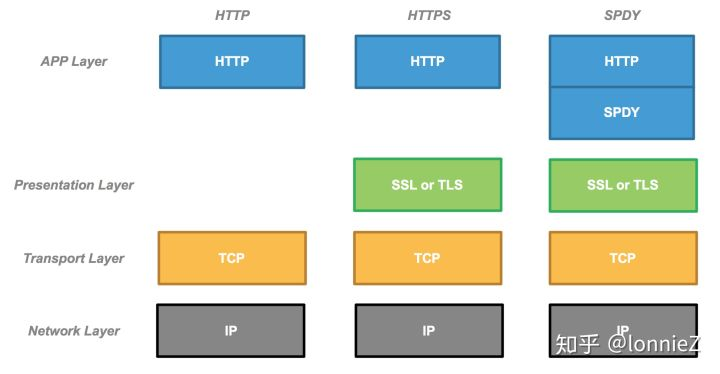
在上面的章节中我们介绍了HTTP协议的一些特点,包括长连接、pipeline、并行连接等。2012年Google推出了SPDY(speedy,翻译为“快速的”)协议,旨在根本上解决HTTP协议中存在的一些问题、提升HTTP的传输效率。而随后诞生的HTTP/2也继承了SPDY的很多特性。因此,在介绍HTTP/2之前,有必要先简单了解一下SPDY的基本特征。首先,我们看一下SPDY的协议栈。由下图可见,SPDY位于HTTP和SSL之间,它属于应用层协议,当发现对端不支持SPDY的情况下,仍然可以延用HTTP/HTTPS协议,因此它可以最大程度的兼容HTTP协议。
SPDY的特性
多路复用(multiplexing)
从上面关于http connection的介绍可以看出,为了提高传输效率,研发人员总是想在每条connection上面尽可能多的传递资源(这是因为建立每条connection都需要消耗较多的资源,例如dns和connect的过程),因此有了keep-alive、pipeline、并行连接等技术。这些技术无不都是在connection上做文章,尽可能的复用这些连接,将它们利用到极致。但是他们都没有彻底解决在一个connection上面同时“收发”多组数据(来自于不同的资源)的问题,虽然pipleline可以同时请求多个资源,但受限于Http层的队头阻塞机制(见上文),在接收的过程中必须按照发送顺序接收。而SPDY的多路复用功能正是解决这个问题。
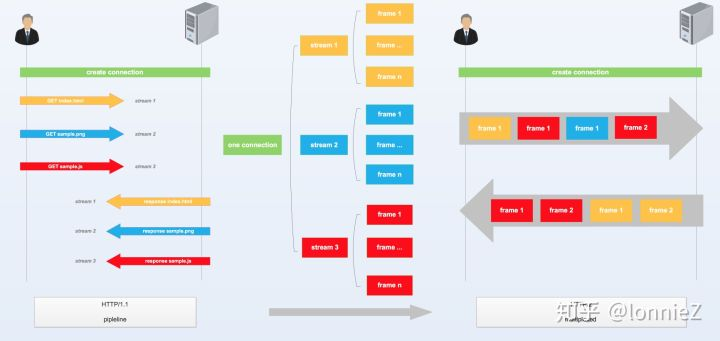
上图显示了Http/1.1与SPDY的对比。从图中可以看出前者虽然采用了pipeline的方式,在一条连接上同时发起了三个请求,但碍于队头阻塞机制,只能按照发送顺序来接收数据,即必须得到index.html后才能得到sample.png的数据。而SPDY则引入了“流(stream)”和“帧(frame)”的概念,将每个完整的request/response过程称为一个“流”(例如图中的GET index.html),再将每个流拆分为多个“帧”(包括数据帧,控制帧等)。通过“流”和“帧”将一个完成request/response过程“打碎”,再将多个“流”的“帧”数据“混在一起”(按照优先级)发送到服务端,服务端再通过流ID和帧ID将数据“还原”,以同样的方式将数据传回给客户端。这样就不会再有队头阻塞的困扰了。
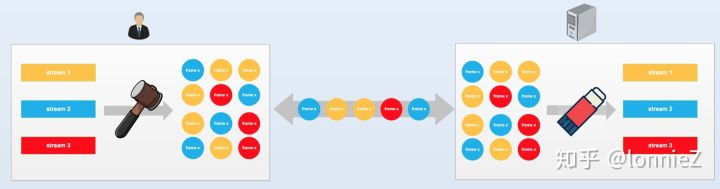
有几点需要注意:
- 一个request和其对应的response组成了一个“流”(stream);
- 每个“流”是由许多个“帧”(frame)组成的,“帧”根据承载内容的不同分为控制帧和数据帧,而控制帧又根据作用的不同分为多种类型的控制帧,包括:同步帧、设置帧、ping帧、header帧等等;
- 每个帧都是二进制数据,这样有利于数据压缩。
请求优先级(request prioritization)
虽然multiplexing解决队头阻塞的问题,但是引入了另一个问题,即如何确保在有限的带宽中优先加载最重要的资源。因为这种multiplexing的机制有可能会影响重要资源的加载。
SPDY允许为每个request设置优先级,这样一些重要的request就可以优先得到响应。例如首页的html就应该优先展示,然后才是一些静态资源文件、脚本文件等,这样就可以确保用户可以第一时间看到页面内容了。
header压缩(Compressed Headers)
在HTTP/1.X中很多header都是重复的甚至多余的,而有些header的内容则比较“庞大”(例如cookie和user-agent等)。由于http的无状态性,header每次会携带一些重复的header信息,造成资源的浪费。因此将header进行压缩不仅可以节省资源,还可以缩短数据传递的延迟。
服务端推送(Server Push)
在HTTP/1.X中只允许从客户端发起请求,然后服务端被动的响应请求。SPDY支持服务端主动发送多个Response给用户端的单个Request。该特性主要应用在当服务端知道它需要发送多个资源来响应单个请求的场景中。如果没有Server Push,那么所有资源都需要客户端一次一次的发起request,而有了Server Push则大大减少了这种本可以避免的往返请求。
Server Push通过在header中添加X-Associated-Content头域(X-开头的头域都属于非标准头域,为自定义头域)来告知客户端会有新的内容推送过来。一般当用户第一次打开网站首页的时候,server端会将很多资源主动推送过来。
SPDY的性能测试
SPDY的性能并非像人们想的那样要由于当前的HTTP/1.X或HTTPS,有些场景下它的性能还不及之前的实现。或者说SPDY提供了一种设计模型,当所有人遵循这个模型的时候,其性能会有提升,而在当前这个比较发散的互联网世界中,制定标准、统一标准始终是一件所有人都期望做但又很难做到的事情,这也是Google所致力于做到的。具体的测试结果及说明可以参见这里。
SPDY的使命
Google在2012年推出Spdy的方案旨在从根本解决HTTP/1.X中存在的诸如连接复用、头部冗余等问题。同时,SPDY也为HTTP/2的制定提供了原型和参考依据。Google与2016年决定不再支持Spdy的开发,这也是为了给HTTP/2让路。但在这短短的四年间,Spdy积累了不少的客户端及服务端参与,这也充分说明了Spdy在解决Http根本性问题上的优势。由此可见,Spdy作为Http/1.X到HTTP/2过渡期的产品,起到了很好的承上启下的衔接作用。
HPACK
在HTTP/1.X中,头部信息是没有压缩的,有些内容是冗余且很占流量(例如User-Agent、Cookie等信息)。因此,在SPDY中引入了头部压缩的机制,它采用DEFLATE算法(存在CRIME的问题),而在HTTP/2中则使用新的压缩算法HPACK。简单来说,HPACK将索引加入到了头部压缩的过程中。即HPACK中会维护一张静态列表和一张动态列表,在静态列表中会预置一些常用的header(详见RFC),当要发送的请求符合静态列表中的内容时,会使用其对应的index进行替换,这样就可以大大压缩头部的size了。下图大体上描述了HPACK的原理:

从下面静态列表可以看出,表中都是一些常用的header信息,当request或response的header中内容与表内的内容相符时,可以使用表中对应的index进行替换。静态表的index大小是固定的61,因此静态表index是从1到61的索引。

动态列表是一个FIFO(队列)的映射表,从index62开始递增。表中的第一个值是最新入队的值,其索引号也是最小的;动态表的大小也是有限制的,当有新的数据要入队列时,就要移除队尾(最老)的数据。每个动态列表与一个TCP连接是一一对应的,即每个动态列表只针对一个TCP连接,每个连接仅有一个动态列表。在HTTP/2中引入了multiplexing机制(准确的说是SPDY引入了multiplexing),对于同一个域名的多个请求都会复用同一个TCP连接。当一个头部没有出现过的时候,就会把其插入到动态列表中,当再有相同内容的头域时就可以通过index替换了。然而,动态列表的大小是有限制的:
动态列表大小=(每个header的字节数+32)*键值对个数
加32的原因是为了头所占用的额外空间和计算头被引用次数而估计的值。
当头域的键值都在索引列表中时按照如下方式进行编码:
1 | 0 1 2 3 4 5 6 7 |
即当头域的键值都在列表中时,第一个bit的值为1,后面是其index值:
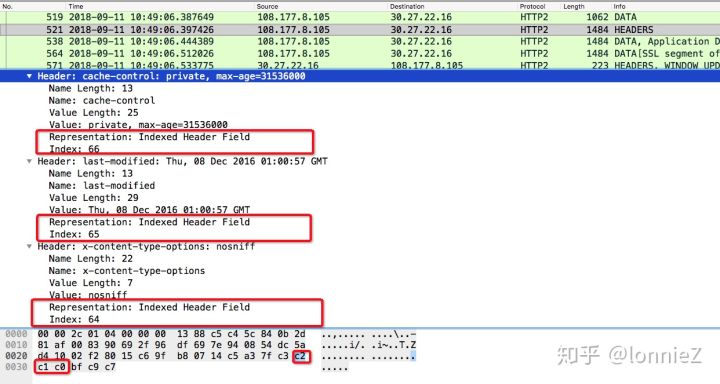
从图中可以看到这里有三个头域分别是cache-control: xxx last-modified: xxx x-content-type-options: xxx 由于这三个头域的键值都已经在列表里面了,因此在这里显示“Indexed Header Field”并且仅仅使用了一个字节来替代。
对于新添加的头域分为几种情况:
- 键在索引中,但值不在
- 键值都不在索引中
- 键在索引中,但值不在,且不要加入到索引中
- 键值都不在索引中,且不要加入到索引中
- 键在索引中,但值不在,且绝对不要加入到索引中
- 键值都不在索引中,且绝对不要加入到索引中
键在索引中,但值不在
1 | 0 1 2 3 4 5 6 7 |
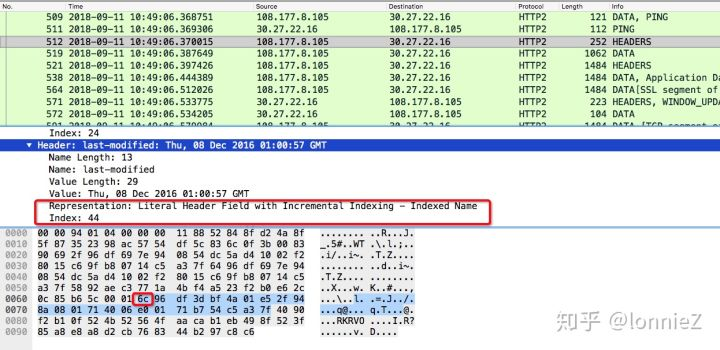
从下面的抓包可以看到last-modifed是在index中的,但是其值并不在,因此这里如果想要将其加入到列表中的话,它的第一个字节为0x6C(01101100),其中前两位是01,后面是101100(index为44)。接下来的一个字节0x96 (10010110)的第一位表示是否使用了霍夫曼编码(此处是),余下的7个字节表示编码长度(此处为22),剩下的内容为霍夫曼编码内容。这里显示为“Incremental Indexing - Indexed Name”,客户端或服务端看到这种格式的头部键值对,会将其添加到自己的动态字典中。后续传输这样的内容,就符合键值都在索引中的情况了
键值都不在索引中
1 | 0 1 2 3 4 5 6 7 |
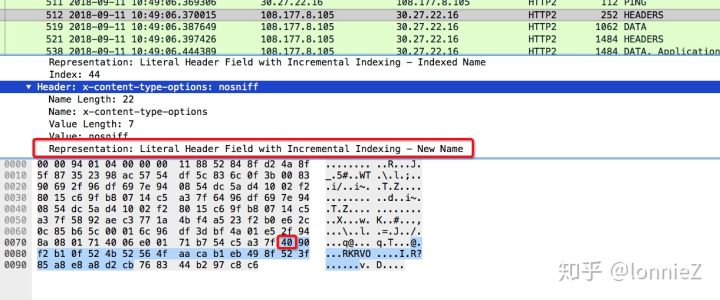
从下面的抓包来看x-content-type-options不在索引中,它属于一个新的头域并且会被加入到索引中(从上面的截图可以看到它后来被加入到了index 64里面)。因此它的第一字节为0x40(01000000)。随后的一个字节是是否使用霍夫曼编码以及编码长度,此处是0x90(10010000),表示键使用霍夫曼,长度为16。随后为0x85(10000101),表示值使用霍夫曼,长度为5。显示为“Incremental Indexing - New Name”,客户端或服务端看到这种格式的头部键值对,会将其添加到自己的动态字典中。后续传输这样的内容,就符合键值都在索引中的情况了
键在索引中,但值不在,且不要加入到索引中
1 | 0 1 2 3 4 5 6 7 |
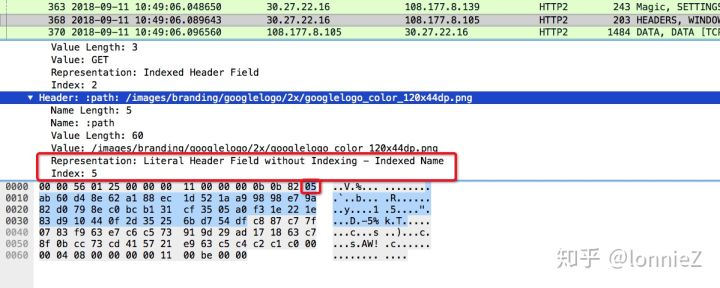
从下面的抓包来看path已经在索引中了,但是客户端不希望该值被保存到索引中,因此设置其为0x05(00000101),后面的一个字节为0xab(10101011),使用霍夫曼编码且长度为43。显示为“without Indexing - Indexed Name”,这种格式的头部键值对,不允许被添加到动态字典中(但可以使用霍夫曼编码)。对于一些敏感头部,比如 Cookie,这么做可以提高安全性。
键值都不在索引中,且不要加入到索引中
1 | 0 1 2 3 4 5 6 7 |
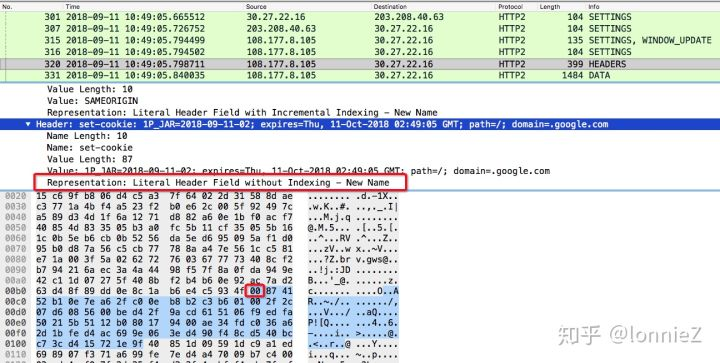
从下面的抓包set-cookie不在索引中且服务端不希望其加入到索引中因此这里的第一个字节为0x00,下一个字节为0x87(10000111),键使用霍夫曼编码且长度为7,值为0xc0(11000000),值使用霍夫曼编码且长度为64。显示为“without indexing - New Name”
键在索引中,但值不在,且绝对不要加入到索引中
1 | 0 1 2 3 4 5 6 7 |
这种情况与之前的“键在索引中,但值不在,且不要加入到索引中”类似,只是第一个字节的第四个bit变为了1,其他是一样的。区别仅在于中间是否通过了代理。如果没有代理,那么表现是一样的。如果通过了代理,则协议要求代理必须原样转发这个header的编码,不允许进行任何修改。
键值都不在索引中,且绝对不要加入到索引中
1 | 0 1 2 3 4 5 6 7 |
同上
更新动态列表大小
1 | 0 1 2 3 4 5 6 7 |
上图是列表大小更新的消息体格式。列表大小可以用至少5个bit表示且最大不超过SETTINGS_HEADER_TABLE_SIZE
在HPACK中,会用到一个或多个字节表示无符号整数,整数的开始并不是在一个字节的开始,但总在一个字节的末尾结束。如下所示,0-2bit可以用于其他标识,那么数值只占了5个bit,因此只能表示2^5-1(例如上面的“更新动态列表大小”的消息)。因此当需要表达的值小于32时,一个字节足够了。
1 | 0 1 2 3 4 5 6 7 |
当超过2^5-1后,此时第一个字节剩下的N个bit必须全为1,第二个字节的首个bit标识是否为最后一个字节,1表示不是,0表示是。剩余字节的值为remain值,假设该值为i,则:remain = i - (2^n - 1);例如:
1 | 0 1 2 3 4 5 6 7 |
N为5,单字节下的取值范围为0-31,现在它为4,再看下面的示例:
1 | 0 1 2 3 4 5 6 7 |
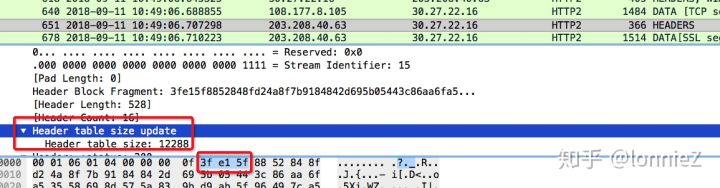
此时,第一个字节的N个bit被占满,第二个字节的首位为0(表示在该字节结束),余下的大小为20,根据公式20 = i - (31)可以计算得出51,再看上面更新动态列表大小”消息中的数值:
1 | 0 1 2 3 4 5 6 7 |
此时第二个字节的首bit为1(表示不在该字节结束),余下大小为 95*(2^7) + 97 其中97为第一个字节排除首bit后的值,95为第二个字节的值,由于第二个字节要往前移动7位(第一个字节用7bit表示数值),因此需要与2^7相乘。根据公式:95*(2^7) + 97 = i - 31 得出最终结果为12288,具体计算算法可以参见这里。
霍夫曼编解码
HPACK中的霍夫曼编解码可以参考这里。我们以上面的“Incremental Indexing - New Name”中的Value举例,这里的值为0x85(10000110),为使用霍夫曼编码且长度为5,后面跟着的5个字节即为编码内容:a8 e8 a8 d2 cb,对应的二进制:
1 | 10101000 11101000 10101000 11010010 11001011 |
参照霍夫曼编码:
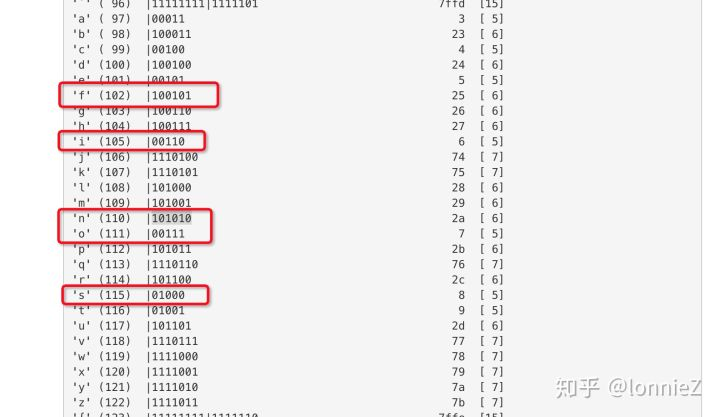
可以得到对应的结果:nosniff