概述 LinkedBlockingQueue是一个单向链表实现的阻塞队列。该队列按 FIFO(先进先出)排序元素,新元素插入到队列的尾部,并且队列获取操作会获得位于队列头部的元素。链接队列的吞吐量通常要高于基于数组的队列,但是在大多数并发应用程序中,其可预知的性能要低。此外,LinkedBlockingQueue还是可选容量的(防止过度膨胀),即可以指定队列的容量。如果不指定,默认容量大小等于Integer.MAX_VALUE。
LinkedBlockingQueue简介
LinkedBlockingQueue源码分析
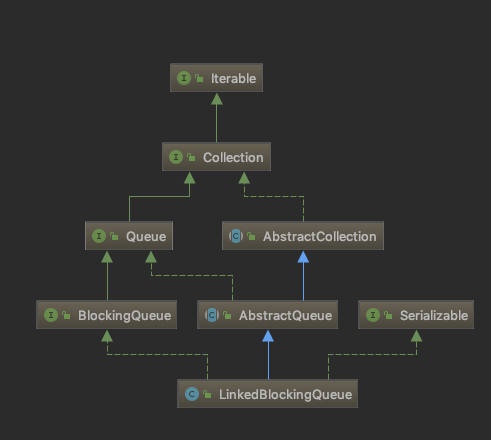
1. LinkedBlockingQueue简介 类图如下
LinkedBlockingQueue继承于AbstractQueue,它本质上是一个FIFO(先进先出)的队列。
LinkedBlockingQueue实现了BlockingQueue接口,它支持多线程并发。当多线程竞争同一个资源时,某线程获取到该资源之后,其它线程需要阻塞等待。
LinkedBlockingQueue是通过单链表实现的,这个是和ArrayBlocking不同的地点。
另外LinkedBlockingQueue使用的是非公平锁,这个不能修改。
LinkedBlockingQueue源码分析 构造函数如下,可以看出LinkedBlockingQueue是可以指定其最大长度,属于有界队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public LinkedBlockingQueue () { this (Integer.MAX_VALUE); } public LinkedBlockingQueue (int capacity) { if (capacity <= 0 ) throw new IllegalArgumentException (); this .capacity = capacity; last = head = new Node <E>(null ); } public LinkedBlockingQueue (Collection<? extends E> c) { this (Integer.MAX_VALUE); final ReentrantLock putLock = this .putLock; putLock.lock(); try { int n = 0 ; for (E e : c) { if (e == null ) throw new NullPointerException (); if (n == capacity) throw new IllegalStateException ("Queue full" ); enqueue(new Node <E>(e)); ++n; } count.set(n); } finally { putLock.unlock(); } }
首先,看一下后面解析重要方法时要用到的属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 static class Node <E> { E item; Node<E> next; Node(E x) { item = x; } } private final int capacity;private final AtomicInteger count = new AtomicInteger ();transient Node<E> head;private transient Node<E> last;private final ReentrantLock takeLock = new ReentrantLock (); private final Condition notEmpty = takeLock.newCondition();private final ReentrantLock putLock = new ReentrantLock ();private final Condition notFull = putLock.newCondition();
构造函数
1 2 3 4 5 6 public LinkedBlockingQueue (int capacity) { if (capacity <= 0 ) throw new IllegalArgumentException (); this .capacity = capacity; last = head = new Node <E>(null ); }
逻辑比较简单,初始化队列长度,并初始化队列的头结点和尾节点,其中节点的数据为null
入队 出队主要由以下方法
1 2 3 4 5 public E put () public boolean offer (E e) public boolean offer (E e, long timeout, TimeUnit unit) public E peek ()
插入大致相同,先获取插入锁,然后将元素入队,最后释放锁。这里拿public boolean offer(E e, long timeout, TimeUnit unit)来举例解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public boolean offer (E e, long timeout, TimeUnit unit) throws InterruptedException { if (e == null ) throw new NullPointerException (); long nanos = unit.toNanos(timeout); int c = -1 ; final ReentrantLock putLock = this .putLock; final AtomicInteger count = this .count; putLock.lockInterruptibly(); try { while (count.get() == capacity) { if (nanos <= 0 ) return false ; nanos = notFull.awaitNanos(nanos); } enqueue(new Node <E>(e)); c = count.getAndIncrement(); if (c + 1 < capacity) notFull.signal(); } finally { putLock.unlock(); } if (c == 0 ) signalNotEmpty(); return true ; } private void enqueue (Node<E> node) { last = last.next = node; } private void signalNotEmpty () { final ReentrantLock takeLock = this .takeLock; takeLock.lock(); try { notEmpty.signal(); } finally { takeLock.unlock(); } }
这里逻辑还是很清楚,但是有一个疑问是,head和last在初始化的时候指向的是同一个节点,那么在进行入队的时候加锁并不会影响出队时的加锁,因为这俩个不是同一个互斥锁。那LinkedBlockingQueue是如何解决入队和出队共同操作同一个对象的呢。其实很简单,就是通过那个原子变量,当入队时,如果检测到队列数量已满,就进行阻塞,当出队时,如果获取到数量为0,则进行出队的阻塞。并且在最后都会有一个非空和未满的信号释放。
下面看看出队你就会更加清楚这种操作。
出队 主要由以下几个接口的实现:
1 2 3 4 public E peek () public E poll () public E poll (long timeout, TimeUnit unit) public E take ()
这里主要讲解public E poll(long timeout, TimeUnit unit)操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public E poll (long timeout, TimeUnit unit) throws InterruptedException { E x = null ; int c = -1 ; long nanos = unit.toNanos(timeout); final AtomicInteger count = this .count; final ReentrantLock takeLock = this .takeLock; takeLock.lockInterruptibly(); try { while (count.get() == 0 ) { if (nanos <= 0 ) return null ; nanos = notEmpty.awaitNanos(nanos); } x = dequeue(); c = count.getAndDecrement(); if (c > 1 ) notEmpty.signal(); } finally { takeLock.unlock(); } if (c == capacity) signalNotFull(); return x; } private void signalNotFull () { final ReentrantLock putLock = this .putLock; putLock.lock(); try { notFull.signal(); } finally { putLock.unlock(); } }
逻辑比较简单,具体的可以看源码中的解释。这里可以验证我们在入队时说的,为了防止入队和出队操作同一个对象也就是last=head这种情况,在入队和出队时,会先进行队列长度的检查,然后在进行操作。这样可以防止出队和入队同时操作同一个对象。
遍历操作 下面对LinkedBlockingQueue的遍历方法进行说明。
1 2 3 public Iterator<E> iterator () { return new Itr (); }
iterator()实际上是返回一个Iter对象。
Itr类的定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 private class Itr implements Iterator <E> { private Node<E> current; private Node<E> lastRet; private E currentElement; Itr() { fullyLock(); try { current = head.next; if (current != null ) currentElement = current.item; } finally { fullyUnlock(); } } public boolean hasNext () { return current != null ; } private Node<E> nextNode (Node<E> p) { for (;;) { Node<E> s = p.next; if (s == p) return head.next; if (s == null || s.item != null ) return s; p = s; } } public E next () { fullyLock(); try { if (current == null ) throw new NoSuchElementException (); E x = currentElement; lastRet = current; current = nextNode(current); currentElement = (current == null ) ? null : current.item; return x; } finally { fullyUnlock(); } } public void remove () { if (lastRet == null ) throw new IllegalStateException (); fullyLock(); try { Node<E> node = lastRet; lastRet = null ; for (Node<E> trail = head, p = trail.next; p != null ; trail = p, p = p.next) { if (p == node) { unlink(p, trail); break ; } } } finally { fullyUnlock(); } } }
从上面可以看出,遍历操作,不一定是准确的反映队列的真实存储,这要看在获取到这个迭代器之后,队列是否发生变化,如果发生了变化,可能会影响遍历的结果。但是一般只是队列头不会如实反映,后面的节点还是会和队列保持一样。这个主要是因为队列的头是被保存下来的,而在遍历时是直接返回保存的节点值。
size 这个操会返回节点数量,是比较准的,所以说他是有界队列时没错的,因为可以精确知道队列的长度,那么就可以精确控制队列长度大小。
1 2 3 public int size () { return count.get(); }
总结 和ArrayBlockingQueue相比,不需要指定队列的长度,默认是整型的最大值,另外这个也是有界队列。只是他的界限可以很大。实现是通过单项链表来实现的。其他的和ArrayBlockQueue实现基本上差不多,不过这个性能比ArrayBlockingQueue要好。ArrayBlockingQueue通过使用全局独占锁实现同时只能有一个线程进行入队或者出队操作,这个锁的粒度比较大。LinkedBlockingQueue入队和出队使用不同的锁,锁的粒度相对于ArrayBlockingQueue来说相对较小。所以并发性上面会更好一点,性能也就更好。